重学Redis-1
B站教程地址:点击跳转
基础篇
p3-认识NoSQL
关系型数据库 VS 非关系型数据库
| SQL | NoSQL | |
|---|---|---|
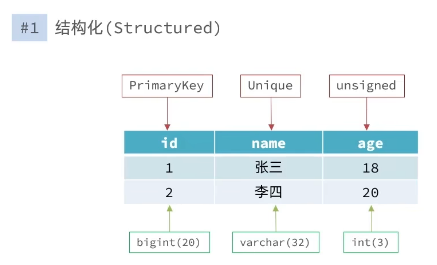
| 结构化(Structured) | 结构化:比如定义用户表:id、name、age。并且可以给id加主键约束,name加唯一约束,age加上无符号整型约束,等等约束。约束定义好了,表的结构就定下来了,插入数据都需要严格遵守这些规定,数据库会对数据进行校验,不符合约束则会报错。结构化数据带来的问题之一:表结构在项目设计之初就应该定下来,后面有修改影响较大。 | 非结构化:如redis是典型的k-v键值存储数据库。对于key-value没有那么强的约束。除了kv还有document型,如json,字段可以是任意的,内容也是任意的,字段约束较为松散。除此之外,还有图graph。 |
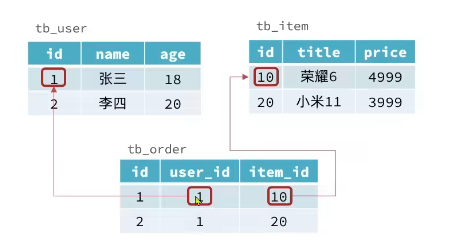
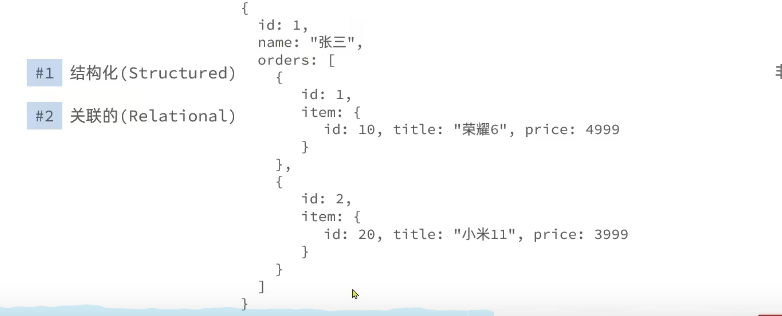
| 关联(Relational) | eg:现在有用户(id,name,age)、商品(id,title,price)、订单(id,user_id,item_id)三张表,订单表关联用户表id和商品表id,就知道谁买了什么商品。表之间通过外键关联,一旦建立关系,当删除数据的时候,不允许,因为在其他表有关联,数据库则会维护他们的关系,关联后可以节省存储空间,在另一张表只需要存储关联表的id就好了。 | 没有表和表之间的外键关系,没有关联。但是有个缺点,数据会重复,如张三买了苹果12.李四也买了。但是手机信息要在两条数据中都保存。数据库不会帮助维护表和表之间的关系,是非关联的。 |
| SQL查询 | 支持SQL查询,格式是固定的,语法也是固定的,只要是关系型数据库,都可以使用相同的语句进行查询。 | 非SQL,没有固定的语法格式。如redis get user:1 ,MongoDb db.users.find({_id:1}),es GET http://localhost:9200/users/1 |
| 事务 | 关系型数据库满足ACID特性 | 无事务或无法满足事务的强一致性 |
| 存储方式(大多数) | 磁盘存储 | 内存存储 |
| 使用场景 | 数据结构固定、业务数据安全性、一致性要求高 | 数据结构不固定、一致性、安全性要求不高、性能要求高 |
| 扩展性 | 垂直(设计之初没有考虑分布式、数据分片需求,存储在本机,虽然支持主从,只是提升了机器数量、无法提升数据存储的量,因为主从是同步的,一样的数据) 可以基于第三方组件实现分库、但是会增加开发难度 | 水平(redis、es在设计之初考虑了数据拆分的需求,在插入数据的时候,会基于数据的id或唯一标识,做哈希运算,根据哈希结果判断数据应该存储在哪个节点上) |
{% gi 3%}
{% endgi %}
p4-认识redis
特征:
- 键值型(key-value),value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性。(redis6多线程是指网络连接是多线程的,命令执行还是单线程)
- 低延迟,速度快(基于内存、IO多路复用、C语言良好的编码)
- 支持数据持久化(rdb,aof)
- redis支持主从集群、分片集群(多态机器存数据,如总共1T,分别存在不同的服务器)
p5-安装redis及三种启动的方式
p6-redis命令行客户端
在安装说明中有详细介绍
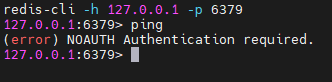
连接
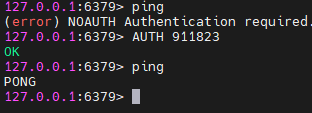
redis-cli -h 127.0.0.1 -p 6379连接后使用ping命令,提示未鉴权。
如果设置了密码,需要在命令中加上-a来输入密码
redis-cli -h 127.0.0.1 -p 6379 -a 911823但是会提示不安全:

所以使用-u来指定密码,或者不指定密码,进入后使用AUTH指定密码:
简单命令
选择库:
select 0简单存取:
set [key] [value]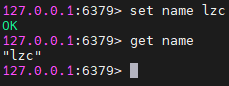
p8-数据结构介绍
redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样:
| value的类型 | 举例 |
|---|---|
| String | hello world |
| Hash | {name:"lzc",age:24} |
| List | [A->B->C->D] |
| Set | {A,B,C} |
| SortedSet | {A:1,B:2,C:3} |
| GEO(地图坐标) | {A:(120.3,30.5)} |
| BitMap | 01101001010001101 |
| HyperLog | 01101001010001101 |
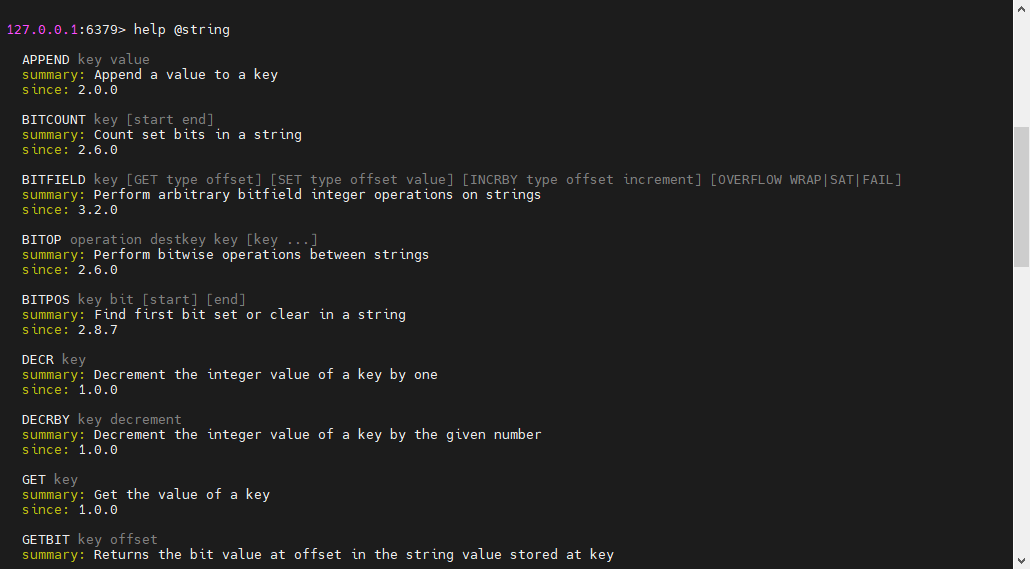
初步学习可以在官方文档查找命令:redis官方命令文档,或者在redis-cli输入help @数据类型,如:
help @string
p9-通用命令
在官方文档过滤generic或者cli输入help @generic可以查看通用命令使用说明。
keys 查找符合模板的所有key,不建议在生成环境设备上使用,如果在主节点上使用会阻塞所有的请求

127.0.0.1:6379> keys n* # 查找n开头的key 1) "name" 127.0.0.1:6379> keys * # 查找所有的key 1) "name"del 删除指定的key 可以删除多个key
127.0.0.1:6379> keys * # 当前所有key 1) "name" 127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 k4 v4 批量插入key-value OK 127.0.0.1:6379> keys * # 查找所有key 1) "name" 2) "k2" 3) "k1" 4) "k3" 5) "k4" 127.0.0.1:6379> del k1 k2 k3 k4 # 删除多个key (integer) 4 127.0.0.1:6379> keys * # 查找所有key 1) "name" 127.0.0.1:6379>exists 判断key是否存在
127.0.0.1:6379> EXISTS name (integer) 1 # 存在返回1 127.0.0.1:6379> EXISTS k1 (integer) 0 # 不存在返回0 127.0.0.1:6379>expire 给一个key设置有效期,有效期到时key会被自动删除。因为redis是基于内存存储,如果在插入key时不设置有效期,默认是永久存储,给key设置有效期可以节省内存空间,如短信验证码,可以设置五分钟,具体根据业务需求设置。
127.0.0.1:6379> help expire # 查询命令 EXPIRE key seconds summary: Set a key's time to live in seconds since: 1.0.0 group: generic 127.0.0.1:6379> expire name 600 # 给key设置有效期(秒) (integer) 1ttl 查看一个key的剩余有效期
127.0.0.1:6379> ttl name # 查询命令有效期 (integer) 485 127.0.0.1:6379>
p10-String类型
String类型,也就是字符串类型,是redis中最简单的存储类型。
其value是字符串,不通过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数型,可以做自增、自减操作
- float:浮点类型,可以做自增、自减操作
不管是哪种格式,底层都是字节数组存储形式,只不过是编码方式不同。字符串类型的最大空间不能超过512M。
| KEY | VALUE | 说明 |
|---|---|---|
| msg | hello world | 将字符转成对应的字节码。如果你愿意,甚至可以将一张图片转成字节,存在redis的string中。 |
| num | 10 | 将字节数组直接转为2进制,一个字节(8位)可以表达很大的数字了。 |
| score | 92.5 | 将字节数组直接转为2进制 |
String常见的命令有:
set 添加或者修改意见存在的一个String类型的键值对
get 根据key获取String类型的value
127.0.0.1:6379> set exam exam OK 127.0.0.1:6379> get exam "exam"mset 批量添加多个String类型的键值对
mget 根据多个key获取多个String类型的value
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 OK 127.0.0.1:6379> mget k1 k2 k3 1) "v1" 2) "v2" 3) "v3" 127.0.0.1:6379>incr 让一个整型的key自增1
127.0.0.1:6379> set num 1 OK 127.0.0.1:6379> incr num (integer) 2 127.0.0.1:6379> incr num (integer) 3 127.0.0.1:6379> incr num (integer) 4 127.0.0.1:6379> DECR num # 自减 (integer) 3 127.0.0.1:6379> DECRBY num 2 # 自减 (integer) 1incrby 让一个key自增指定步长,如 incrby num 2,让num自增2,自减decrby或者自增时给负数即可
127.0.0.1:6379> incrby num 2 (integer) 6 127.0.0.1:6379>incrbyfloat 让一个浮点型的数字自增指定步长,自减给负数即可
127.0.0.1:6379> incr floatnum # 浮点型不可用该命令自增 (error) ERR value is not an integer or out of range 127.0.0.1:6379> incrbyfloat floatnum 0.1 "1.2" 127.0.0.1:6379>setnx 添加一个String类型的键值对,前提是这个key不存在,否则不执行
127.0.0.1:6379> keys * 1) "exam" 2) "num" 3) "k2" 4) "k1" 5) "k3" 6) "float" 7) "floatnum" 127.0.0.1:6379> setnx exam examnx (integer) 0 # exam已经存在,不执行,返回0 127.0.0.1:6379> setnx name lzc (integer) 1 # name不存在,执行,返回1 127.0.0.1:6379> set name lzc nx # set后面跟nx和setnx效果类似 (nil) # 已存在,不执行 127.0.0.1:6379> set name1 lzc nx OK # 不存在,执行setex 添加一个String类型的键值对,在保存key的同时指定有效期,相当于set 和expire结合
127.0.0.1:6379> setex name2 100 lzc OK 127.0.0.1:6379> ttl name2 (integer) 97
p11-Key的层级格式
Redis中没有类似MySQL中Table的概念,我们该如何区分不同类型的key呢?
- 例如,需要存储用户、商品信息到redis中,有一个用户id是1,有一个商品的id恰好也是1
key的结构:redis中的key允许多个单词形成层级结构,多个单词之间用:隔开,格式如下:
项目名:业务名:类型:id
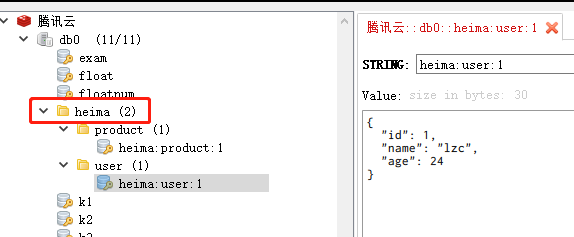
这个格式非固定的,也可以根据自己的需求来添加或删除词条,例如项目名字叫heima,有user和product两种不同类型的数据,我们可以这样定义key:
- user相关的key:heima:user:1
- product相关的key:heima:product:1
如果value是一个Java对象,例如一个User对象,则可以将对象序列化为json字符串后存储:
| KEY | VALUE |
|---|---|
| heima:user:1 | {"id":1,"name":"lzc","age":24} |
| heima:product:1 | {"id":1,"name":"IPhone12","price":8499} |
127.0.0.1:6379> set heima:user:1 '{"id":1,"name":"lzc","age":24}'
OK
127.0.0.1:6379> set heima:product:1 '{"id":1,"name":"IPhone12","price":8499}'
OK
127.0.0.1:6379> mget heima:user:1 heima:product:1
1) "{\"id\":1,\"name\":\"lzc\",\"age\":24}"
2) "{\"id\":1,\"name\":\"IPhone12\",\"price\":8499}"
当通过图形化界面查看时,可以很好的区分层级:
p12-Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似Java中的HashMap结构。
String结构是将对象序列化为json字符串后存储,当需要修改对象某个字段时很不方便:
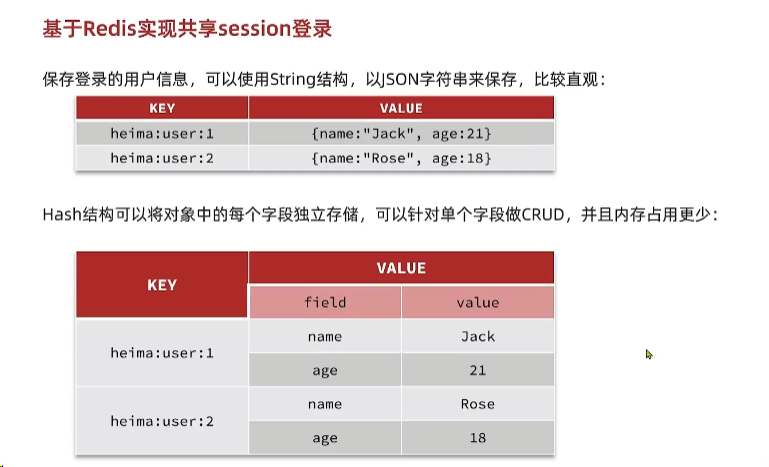
| KEY | VALUE |
|---|---|
| heima:user:1 | {name:"jack",age:21} |
| heima:user:2 | {name:"rose",age:18} |
Hash结构可以将对象中的每个字段独立存储。可以针对单个字段做CRUD:
| KEY | VALUE | |
|---|---|---|
| KEY | field | value |
| heima:user:1 | name | jack |
| age | 21 | |
| heima:user:2 | name | rose |
| age | 18 | |
Hash常见命令有:
hset key field value:添加或修改hash类型key的field的值
hget key field:获取hash类型key的field的值
127.0.0.1:6379> hset examMap user:1 100 # 设置用户id为1的考试成绩为100 (integer) 1 127.0.0.1:6379> HGET examMap user:1 # 获取用户id为1的考试成绩 "100" 127.0.0.1:6379>hmset :批量添加多个hash类型的key的field的值,在给key赋值时可以给多个字段,值赋值
hmget : 批量获取多个hash类型的key的field的值,获取key的时候可以指定获取多个字段的值。
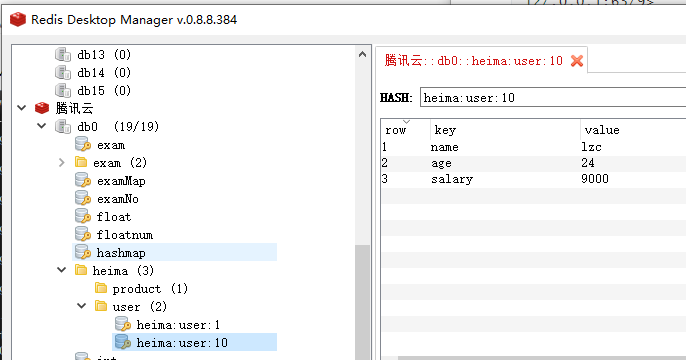
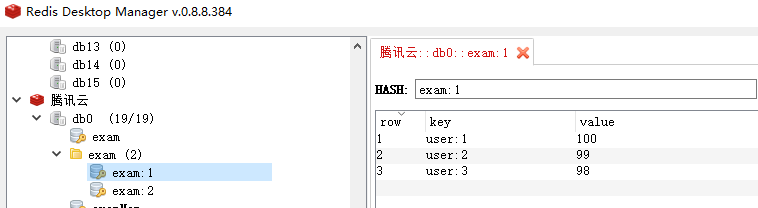
127.0.0.1:6379> help HMSET HMSET key field value [field value ...] summary: Set multiple hash fields to multiple values since: 2.0.0 group: hash # 批量插入考试id为1 的多个用户的考试成绩 127.0.0.1:6379> hmset exam:1 user:1 100 user:2 99 user:3 98 OK # 批量获取考试id为1 的多个用户的考试成绩 127.0.0.1:6379> hmget exam:1 user:1 user:2 user:3 1) "100" 2) "99" 3) "98" # 设置用户id为10 的姓名、年龄 月薪 127.0.0.1:6379> HMSET heima:user:10 name lzc age 24 salary 9000 # 批量获取 127.0.0.1:6379> HMGET heima:user:10 name age salary 1) "lzc" 2) "24" 3) "9000"{% gi 2%}
{% endgi %}
hgetall :获取也一个hash类型中的所有的field和value,key和value依次返回。
127.0.0.1:6379> hgetall heima:user:10 1) "name" 2) "lzc" 3) "age" 4) "24" 5) "salary" 6) "9000" 127.0.0.1:6379>hkeys :获取一个hash类型中的所有的字段(field)
127.0.0.1:6379> hkeys heima:user:10 1) "name" 2) "age" 3) "salary"hvals :获取一个hash类型中所有字段(field)的值
127.0.0.1:6379> hvals heima:user:10 1) "lzc" 2) "24" 3) "9000"hincrby :让hash类型中的某个字段(field)自增指定值
127.0.0.1:6379> hincrby heima:user:10 age 1 年龄自增1 (integer) 25 127.0.0.1:6379> hget heima:user:10 age "25" 127.0.0.1:6379> hvals heima:user:10 1) "lzc" 2) "25" 3) "9000"hsetnx :添加一个hash类型的字段,如果不存在则添加,存在不执行,与setnx不同的是,setnx是判断key是否存在,而hsetnx是判断某个字段(field)是否存在。
127.0.0.1:6379> hsetnx heima:user:10 age 100 # age字段已经存在,不执行,返回0 (integer) 0 127.0.0.1:6379> hsetnx heima:user:10 age1 100 # age1字段不存在,执行,返回1 (integer) 1 127.0.0.1:6379> hvals heima:user:10 1) "lzc" 2) "25" # age字段已存在,不执行,不改变值 3) "9000" 4) "100" # age1字段不存在,执行,hash中多了age1这个字段
p13-List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索,也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快(改变指针指向即可,无需移动元素或扩容)
- 查询速度一般(只能通过next指针逐个遍历)
List的常见命令有:
lpush key element ...:向列表左侧插入一个或多个元素
127.0.0.1:6379> lpush users 1 2 3 (integer) 3由于是从左侧插入元素,所以最终结果是:3->2->1
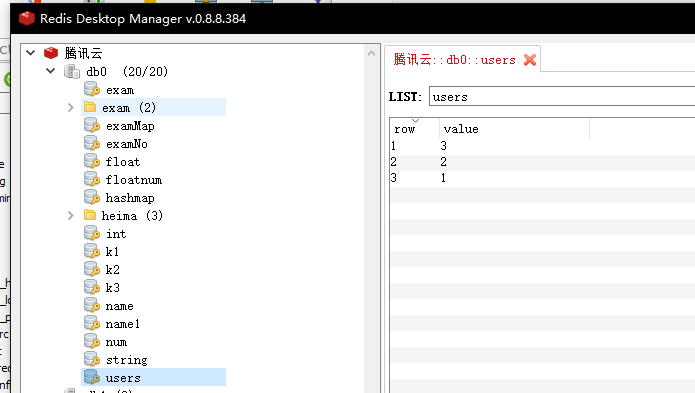
rpush key element ...:向列表右侧插入一个或多个元素
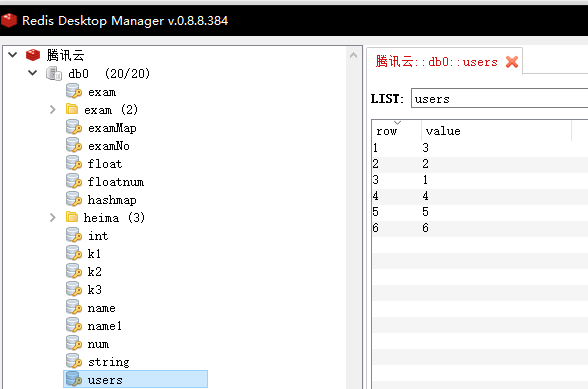
127.0.0.1:6379> rpush users 4 5 6 (integer) 6由于是从右侧插入元素,所以最终结果是:3->2->1->4->5->6
lpop key [count] :从列表左边移除一个值,并返回(类似C语言数据结构中的栈)
127.0.0.1:6379> lpop users 1 1) "3"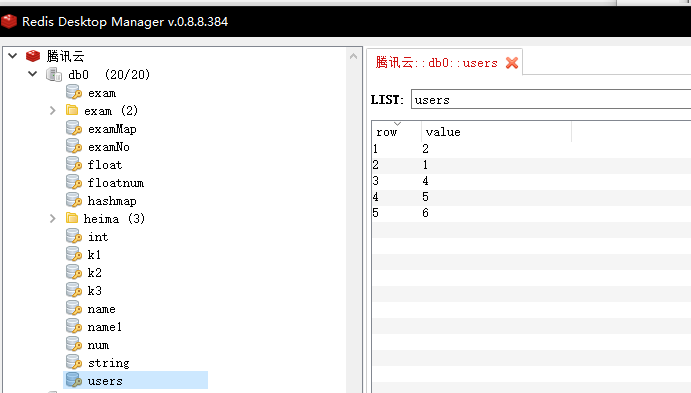
rpop key [count] :从列表右边移除一个值,并返回
127.0.0.1:6379> rpop users 1 1) "6"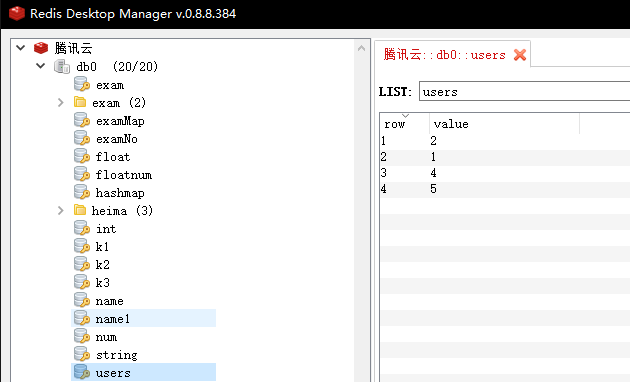
lrange key [start] [end] : 返回(不会移除)一段角标范围内的所有元素(从0开始)
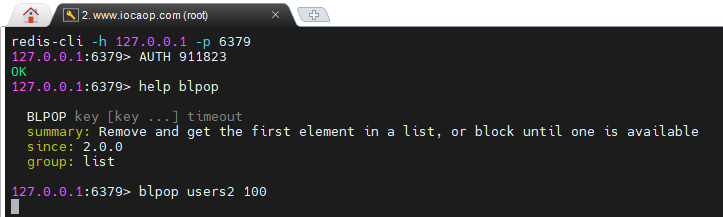
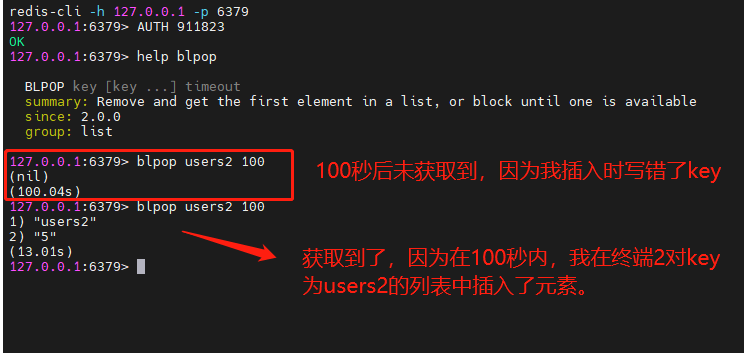
127.0.0.1:6379> lrange users 1 2 1) "1" 2) "4"blpop和brpop :与lpop和rpop类似,只不过blpop和brpop在没有元素时等待指定时间,而不是返回nil,是阻塞式移除。
终端1:获取key为users2的列表中的所有元素,设置等待100秒
终端2:插入
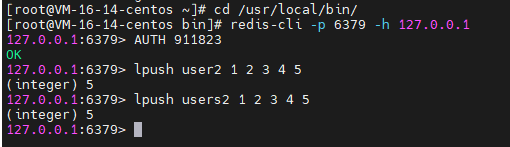
终端1:查看结果
思考:
如何利用List结构模拟一个栈?
入口和出口在同一边。比如lpush进,lpop出
如何利用List结构模拟一个队列?
入口和出口不在同一边。比如lpush进,rpop出
如何利用List结构模拟一个阻塞队列?
出口和入口在不同边,且使用阻塞式移除。比如lpush进,brpop出。或者rpush进,blpop出。
p14-Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集、并集、差集等功能
Set的常见命令有:
sadd key member ... :向set中添加一个或多个元素
smembers key:获取set中所有元素
127.0.0.1:6379> sadd s1 a b c a # 添加了两个a (integer) 3 127.0.0.1:6379> smembers s1 1) "b" 2) "c" 3) "a" # set中只有一个a,因为元素不可重复srem key member ... :移除set中指定的元素
127.0.0.1:6379> srem s1 a b # 移除s1中的a和b (integer) 2 127.0.0.1:6379> smembers s1 1) "c"sismember key member :判断一个元素是否存在set中
127.0.0.1:6379> sismember s1 a # 元素a已删除,不在s1中,返回0 (integer) 0 127.0.0.1:6379> sismember s1 c # 元素c在s1中,返回1 (integer) 1scard key 查询set中的元素个数
127.0.0.1:6379> scard s1 (integer) 1 # 当前有一个元素c 127.0.0.1:6379> sadd s1 d e f (integer) 3 # 新增元素d e f 127.0.0.1:6379> scard s1 (integer) 4 # 当前有4个元素sinter key1 key2 ... :求key1与key2的交集
127.0.0.1:6379> smembers s1 1) "f" 2) "c" 3) "e" 4) "d" 127.0.0.1:6379> smembers s2 1) "b" 2) "c" 3) "d" 4) "a" 127.0.0.1:6379> sinter s1 s2 # 求交集 1) "c" 2) "d"sdiff key1 key2 ... :求key1和key2的差集
127.0.0.1:6379> smembers s1 1) "f" 2) "c" 3) "e" 4) "d" 127.0.0.1:6379> smembers s2 1) "b" 2) "c" 3) "d" 4) "a" 127.0.0.1:6379> sdiff s1 s2 1) "f" 2) "e" # 求差集 s1有的而s2没有的 127.0.0.1:6379> sdiff s2 s1 1) "b" 2) "a" # 求差集 s2有的而s1没有的sunion key1 key2 ... :求key1和key2的并集(去重)
127.0.0.1:6379> sunion s1 s2 1) "b" 2) "c" 3) "a" 4) "f" 5) "e" 6) "d" # 求s1和s2的并集,并去重
set命令练习
将下列数据用Redis的Set集合来存储:
张三的好友有:李四、王五、赵六
李四的好友有:王五、麻子、二狗
127.0.0.1:6379> sadd friend:zhangsan lisi wangwu zhaoliu (integer) 3 127.0.0.1:6379> sadd friend:lisi wangwu mazi ergou (integer) 3
利用Set命令实现下列功能
计算张三的好友有几个
127.0.0.1:6379> scard friend:zhangsan (integer) 3计算张三和李四有哪些共同好友
127.0.0.1:6379> sinter friend:zhangsan friend:lisi 1) "wangwu"查询哪些人是张三的好友却不是李四的好友
127.0.0.1:6379> sdiff friend:zhangsan friend:lisi 1) "zhaoliu" 2) "lisi"查询张三和李四的好友总共有那些人
127.0.0.1:6379> sunion friend:zhangsan friend:lisi 1) "lisi" 2) "wangwu" 3) "zhaoliu" 4) "ergou" 5) "mazi"判断李四是否是张三的朋友
127.0.0.1:6379> sismember friend:zhangsan lisi (integer) 1判断张三是否是李四的朋友
127.0.0.1:6379> sismember friend:lisi zhangsan (integer) 0将李四从张三的好友列表中移除
127.0.0.1:6379> srem friend:zhangsan lisi (integer) 1 127.0.0.1:6379> smembers friend:zhangsan 1) "zhaoliu" 2) "wangwu"
p15-SortedSet
Redis的SortedSet是一个可排序的集合,和Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层是一个跳表(SkipList)加Hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
因为SortedSet的可排序特性,经常用来实现排行榜这样的功能。
SortedSet命令练习
将班级的下列学生得分存入Redis的SortedSet中:
Jack 85,Lucy 89,Rose 82 ,Tom 95,Jerry 78,Amy 92,Miles 76
并实现下列功能
- 删除Tom同学
- 获取Amy同学的分数
- 获取Rose同学的排名
- 查询80以下有几个学生
- 给Amy同学加2分
- 查出成绩前3名的同学
- 查出成绩80分以下的所有同学
结合命令实现:
- 存储学生成绩 :zadd score member
127.0.0.1:6379> help zadd
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...]
summary: Add one or more members to a sorted set, or update its score if it already exists
since: 1.2.0
group: sorted_set
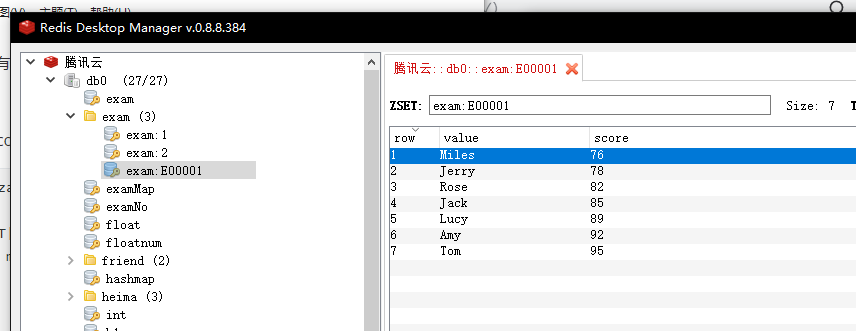
127.0.0.1:6379> zadd exam:E00001 85 Jack 89 Lucy 82 Rose 95 Tom 78 Jerry 92 Amy 76 Miles
(integer) 7
删除Tom同学
127.0.0.1:6379> zrem exam:E00001 Tom (integer) 1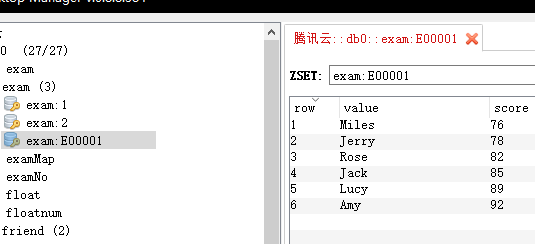
获取Rose同学的排名
降序 127.0.0.1:6379> zrevrank exam:E00001 Rose (integer) 3 # 倒数第四个 升序 127.0.0.1:6379> zrank exam:E00001 Rose (integer) 2 # 第三个 从0开始计查询现在存储了多少学生的成绩
127.0.0.1:6379> zcard exam:E00001 (integer) 6查询80分以下的学生有多少
127.0.0.1:6379> zcount exam:E00001 0 80 (integer) 2 # 80分以下的只有两个,Miles和Jerry给Amy加2分
127.0.0.1:6379> zincrby exam:E00001 2 Amy "94"查出成绩前三名的所有同学
# 可以看到,默认是升序,所以zange查出来的是升序结果,是倒数三名 127.0.0.1:6379> zrange exam:E00001 0 2 1) "Miles" 2) "Jerry" 3) "Rose" # 查前三名应该查降序排名的前三名,所以用zrevrange 127.0.0.1:6379> zrevrange exam:E00001 0 2 1) "Amy" 2) "Lucy" 3) "Jack"查出成绩在80以下的所有同学
127.0.0.1:6379> zrangebyscore exam:E00001 0 80 1) "Miles" 2) "Jerry"
p16-Redis的Java客户端
- Jedis:以Redis命令作为方法名称,比如redis中string的set方法在jedis中就是set。学习成本低,简单实用,但是Jedis实例是线程不安全的,多线程环境下需要基于连接池来使用。
- lettuce :基于Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。与Spring结合比较好,响应式编程、异步编程吞吐能力高。
- Redisson:基于Redis实现的分布式、可伸缩的Java数据结构集合。包含了诸如Map、Queue、Lock、semaphore、AtomicLong等强大功能。如果在分布式环境下有使用这些数据结构的需求,就可以不用自己造轮子了。
Jedis的使用:
引入依赖
<!--jedis--> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.2.3</version> </dependency> <!-- 单元测试 --> <dependency> <groupId>org.junit.jupiter</groupId> <artifactId>junit-jupiter</artifactId> <version>5.7.0</version> <scope>test</scope> </dependency>建立连接方法
/** * 连接 */ @BeforeEach void setUp() { // 建立连接 jedis = new Jedis("www.iocaop.com", 6379); // 设置密码 jedis.auth("****"); // 选择库 jedis.select(0); }释放连接方法
/** * 释放连接 */ @AfterEach void tearDown() { if (null != jedis) { jedis.close(); } }测试简单set、get命令
/** * 测试get、set命令 */ @Test void testString() { String result = jedis.set("name", "lzc"); System.out.println(result); String name = jedis.get("name"); System.out.println(name); }
测试Hash
@Test void testHash(){ // 插入hash数据 用户id为1的姓名 long nameResult = jedis.hset("user:1", "name", "lzc"); System.out.println(nameResult); // 插入hash数据 用户id为1的年龄 long ageResult = jedis.hset("user:1", "age", "24"); System.out.println(ageResult); // 获取hash数据 用户id为1的姓名 String examLzcName = jedis.hget("user:1", "name"); System.out.println(examLzcName); // 获取hash数据 用户id为1的年龄 String examLzcAge = jedis.hget("user:1", "age"); System.out.println(examLzcAge); }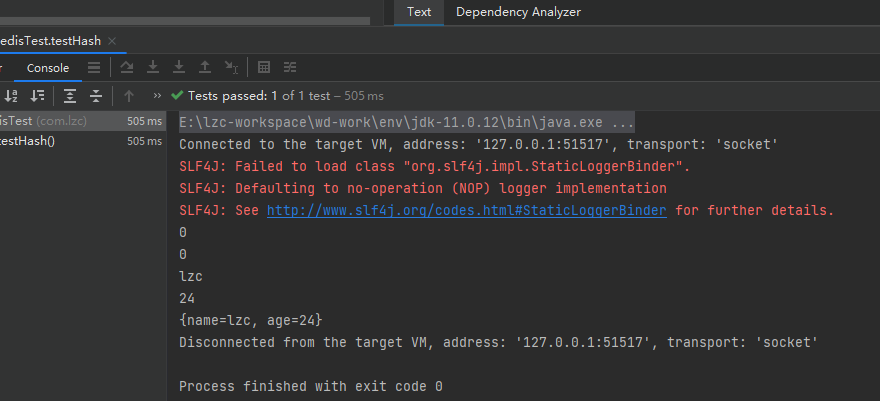
Jedis使用和redis-cli使用一样,方法名称就是redis的命令,需要注意的是最后需要释放连接
p18-Jedis的连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,因此使用Jedis连接池代替Jedis直连。
public class JedisConnectionFactory {
/**
* 创建连接池
*/
private static JedisPool jedisPool = null;
// 使用静态代码块,初始化连接池
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 连接池中最大连接数
jedisPoolConfig.setMaxTotal(8);
// 连接池中最大空闲连接数:即使没有链接的时候,也可以保持8个空闲的连接,即使不使用,也不会被清除
jedisPoolConfig.setMaxIdle(8);
// 连接池中最小空闲连接数:当连接数少于此值时,连接池会创建连接来补充到该值的数量
jedisPoolConfig.setMinIdle(1);
// 连接池中连接超时时间
jedisPoolConfig.setMaxWaitMillis(1000);
jedisPool = new JedisPool(jedisPoolConfig,"150.158.20.104",6379,1000,"911823");
}
/**
* 获取Jedis实例
*
* @return {@link Jedis}
*/
public Jedis getJedis() {
return jedisPool.getResource();
}
}
p19-SpringData-Redis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis。
- 提供了对不动Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate同一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、Spring对象的数据序列化和反序列化
- 支持基于Redis的JDKCollection实现
在Jedis的Java客户端中,操作数据时,key和value都是字符串类型,或者是字节(Redis的底层编码都是字节数组,编码格式不一样而已),Java对象需要存储,Jedis则需要手动序列化,变成字符串再存储。RedisTemplate就本身支持将Java对象序列化成字符串或字节数组往Redis中写入,或者将Redis中读取到的字节数组或字符串反序列化成Java对象。除此之外,RedisTemplate还基于Redis对集合重新做了实现(因为是跨系统的,分布式的)。
Redis中,对命令进行了分组,如字符串用set、get,哈希用hset、hget。同样,在RedisTemplate中也对命令做了分组:
| API | 返回值类型 | 说明 |
|---|---|---|
| redisTemplate.opsForValue() | ValueOperations | 操作String类型数据 |
| redisTemplate.opsForHash() | HashOperations | 操作Hash类型数据 |
| redisTemplate.opsForList() | ListOperations | 操作List类型数据 |
| redisTemplate.opsForSet() | SetOperations | 操作Set类型数据 |
| redisTemplate.opsForZSet | ZSetOperations | 操作SortedSet类型数据 |
| redisTemplate | 通用命令 |
p20-RedisTemplate
因为SpringData是基于SpringBoot的,所以需要先创建Springboot项目。
集成父项目:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.6</version>
</parent>
引入启动器依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
springboot-data-redis依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
连接池依赖:
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
其他依赖
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
由于现在使用了Springboot,所以不需要手动去创建Jedis/Lettuce连接对象(无论是Jedis还是Lettuce都会基于commons-pool实现连接池效果),交给ioc管理了,所以需要创建application.yml配置连接即可。需要注意的是spring默认使用的是lettuce客户端,如果需要使用Jedis,需要额外引入Jedis依赖。
spring:
data:
redis: # redis data
host: www.iocaop.com # redis服务器地址
port: 6379 # 端口号
password: 911823 # 密码用password字段,而不是auth
database: 0 # 数据库编号
lettuce:
pool:
maxActive: 10 #最大连接数
minIdle: 5 #最小空闲连接数
maxIdle: 10 #最大空闲连接数
maxWait: 1000 #最长等待时间
创建启动类
@SpringBootApplication
public class RedisDemoApplication {
public static void main(String[] args) {
SpringApplication.run(RedisDemoApplication.class, args);
}
}
创建测试类
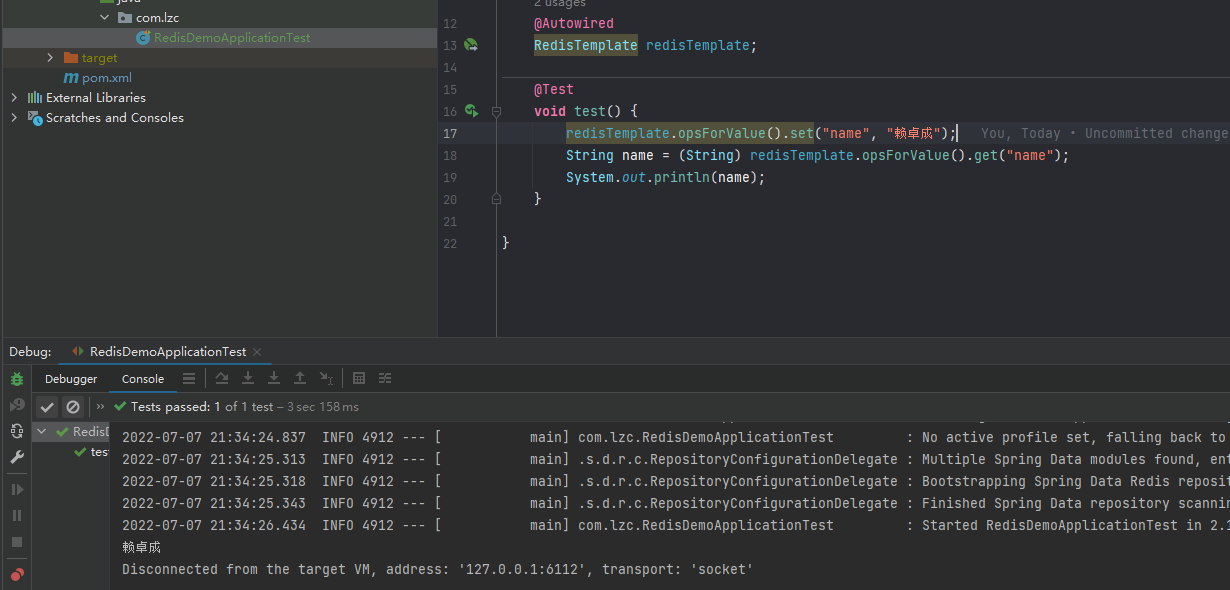
@SpringBootTest
class RedisDemoApplicationTest {
@Autowired
RedisTemplate redisTemplate;
@Test
void test() {
redisTemplate.opsForValue().set("name", "赖卓成");
String name = (String) redisTemplate.opsForValue().get("name");
System.out.println(name);
}
}
运行结果:
p21-RedisTemplata的RedisSerializer
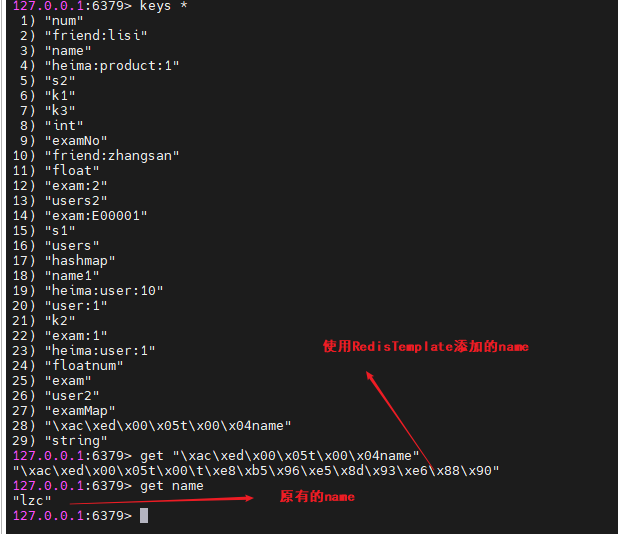
运行完上一节课的命令后,我们到redis-cli中查看name,发现值是lzc,而不是赖卓成:
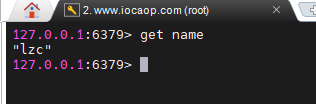
把所有的key显示出来,key发现,我们使用RedisTemplate保存的key不是name而是"\xac\xed\x00\x05t\x00\x04name"
这就不得不提到RedisTemplate的序列化。
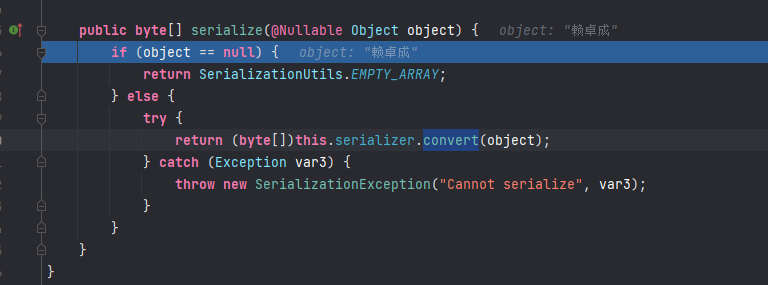
点进RedisTemplate源码可以看到,有多种序列化器,默认值是null。当我们不配置序列化器时,会使用默认序列化器。
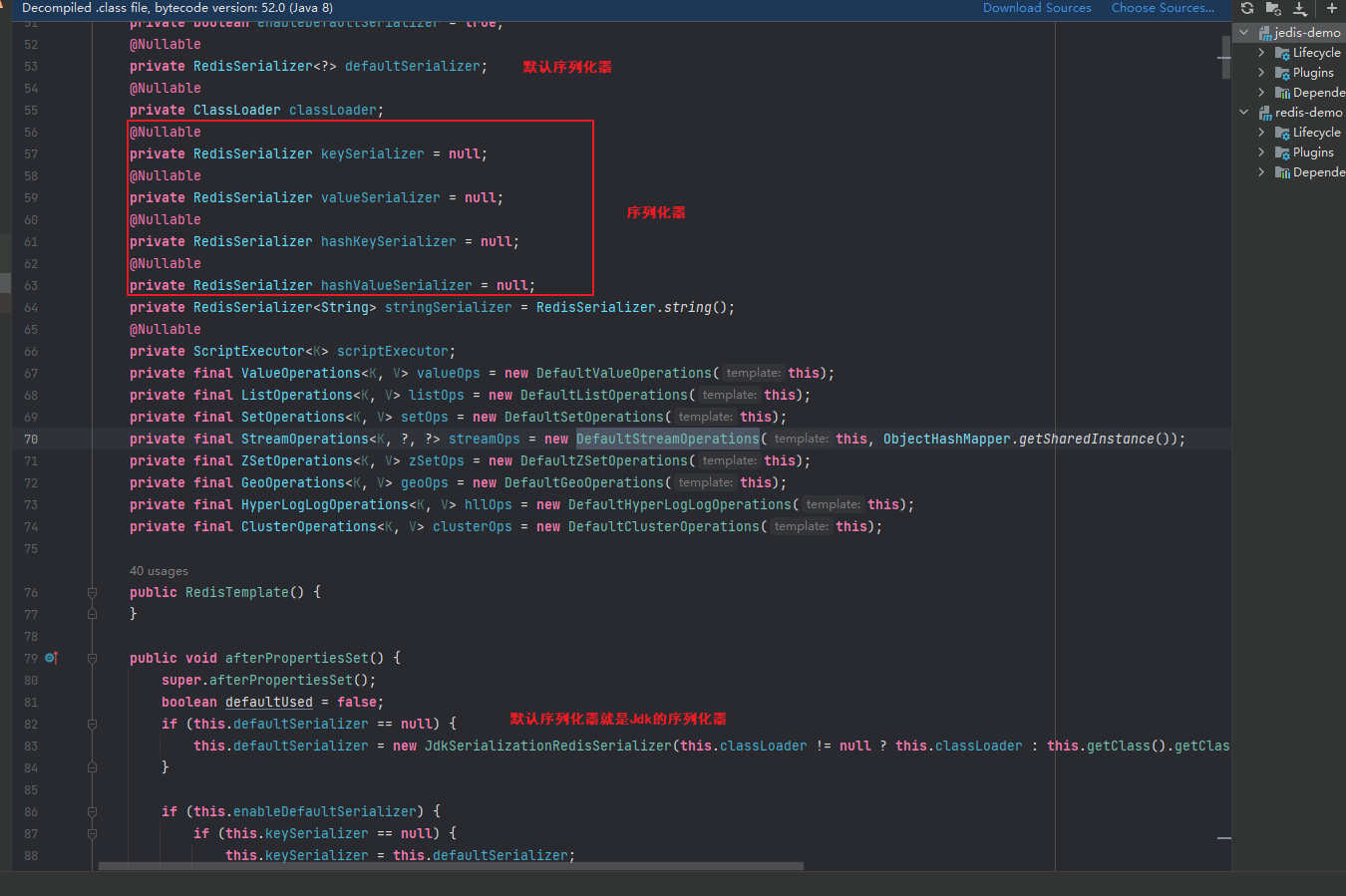
我们可以打断点跟入:选定方法后按f7
{% gi 2%}





{% endgi %}
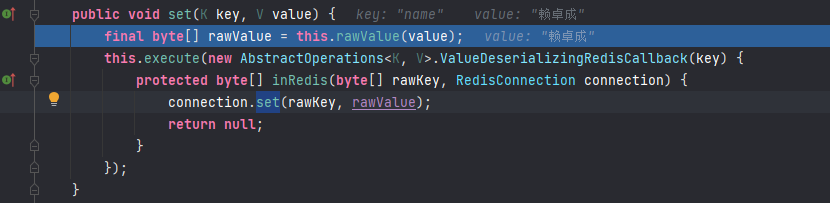
到此为止可以看出最终使用的是ObjectOutputStream,也就是jdk的序列化器,将Java对象转为字节数组后存储到Redis。
这样的方式有什么问题?
- 可读性差
- 出现bug,我们明明set的name是赖卓成,get时却是lzc。因为key也被序列化。
- 内存占用太大。
我们希望我们set的是什么就是什么,需要怎么做?
更换序列化器即可。
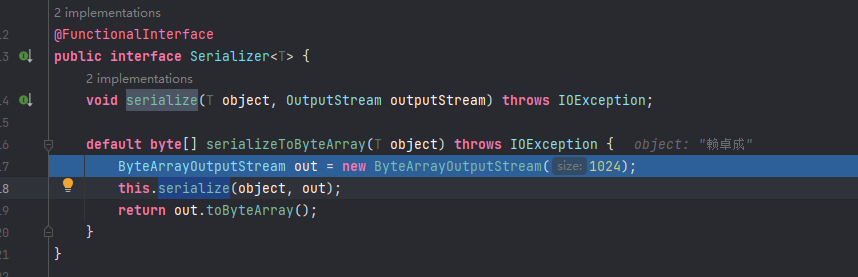
在RedisTemplate中有许多成员变量,序列化器:RedisSerializer。我们进入序列化器类,按Ctrl+Alt+B查看实现类:

其中StringRedisSerializer用于将字符串转成字节数组(Redis中的数据本身也存储的是字节数组)。key一般就是字符串,所以key一般用StringRedisSerializer,如果有特殊需要可以更换key的序列化器。
可以在配置类中配置:
@Configuration
public class RedisConfig {
/**
* 我们默认key都是String类型,value是Object类型,所以我们需要自定义一个RedisTemplate<String, Object>
*
* @param redisConnectionFactory Redis连接工厂,SpringBoot会创建,注入就可以了
* @return {@link RedisTemplate}<{@link String}, {@link Object}>
*/
@Bean
RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory){
// 创建redisTemplate
RedisTemplate<String,Object> redisTemplate = new RedisTemplate<>();
// 配置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 创建json序列化器
GenericJackson2JsonRedisSerializer serializer = new GenericJackson2JsonRedisSerializer();
// 设置key序列化器 key就是字符串类型,用stringRedisSerializer序列化器就好了
redisTemplate.setKeySerializer(RedisSerializer.string());
// 设置hashKey序列化器
redisTemplate.setHashKeySerializer(RedisSerializer.string());
// 设置value序列化器 就是我们自定义的序列化器serializer
redisTemplate.setValueSerializer(serializer);
// 设置hashValue序列化器
redisTemplate.setHashValueSerializer(serializer);
return redisTemplate;
}
}
配置以后,我们需要在注入时带上泛型。
@Autowired
RedisTemplate<String,Object> redisTemplate;
运行:
再到官方redis-cli查看:
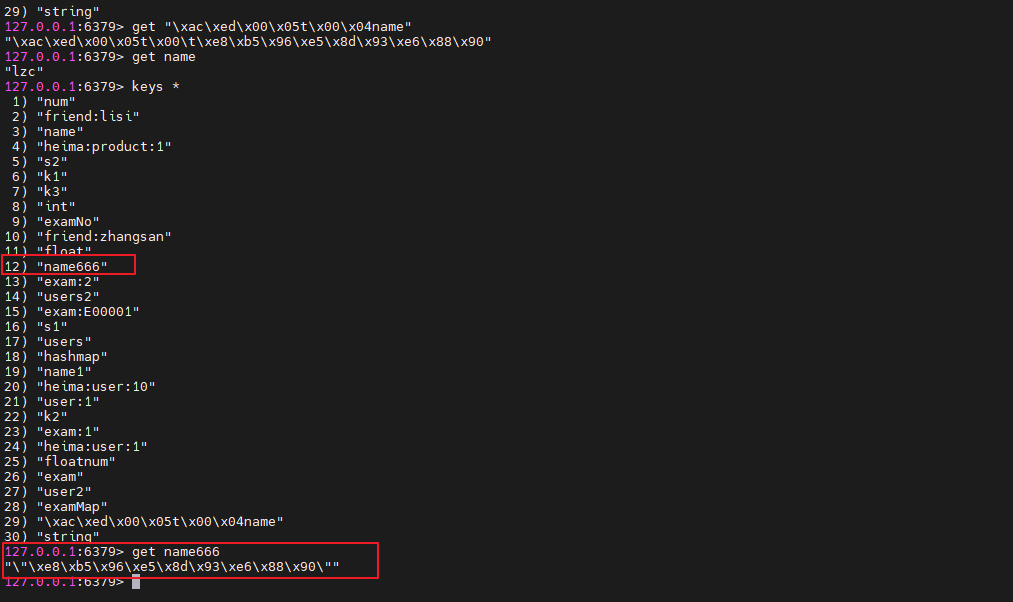
可以看到,key是name666,存到redis以后也是666。
我们再尝试下pojo存储
@Data
public class User {
/**
* 名字
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 地址
*/
private String address;
}
@SpringBootTest
class RedisDemoApplicationTest {
@Autowired
RedisTemplate<String,Object> redisTemplate;
@Test
void test() {
User user = new User();
user.setName("赖卓成");
user.setAge(24);
user.setAddress("广东深圳");
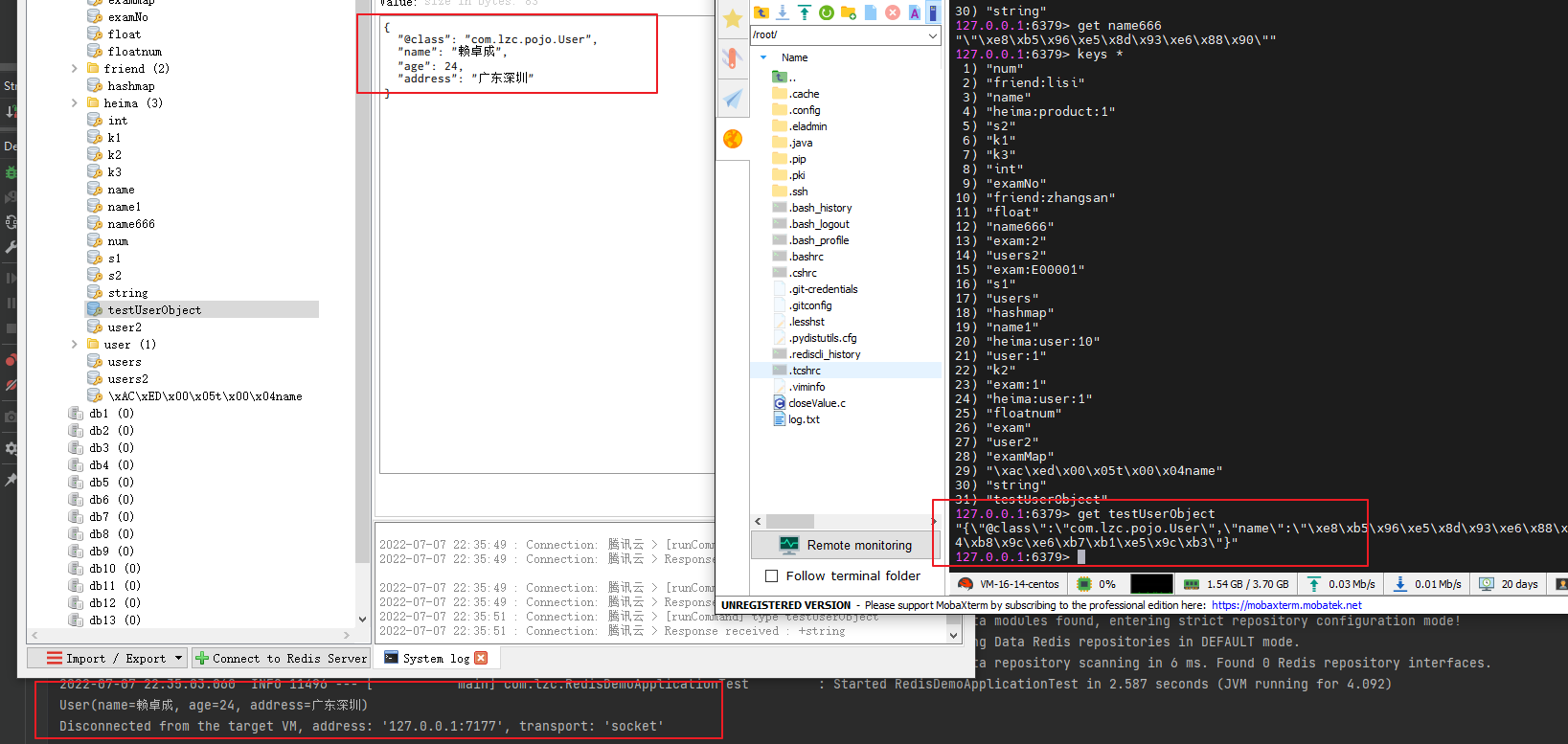
redisTemplate.opsForValue().set("testUserObject", user);
// 取redis值时,RedisTemplate可以根据值的第一行 "@class": "com.lzc.pojo.User",反序列化成User对象,所以这里可以直接强转,
User redisUser = (User) redisTemplate.opsForValue().get("testUserObject");
System.out.println(redisUser);
}
}
p22-StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但还是存在问题:
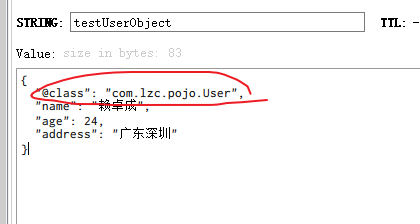
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,增加了内存开销。
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value,当需要存储Java对象时,手动完成对象的序列化和反序列化。

Spring默认提供了一个StringRedisTemplata类,它的key和value的序列化方式默认是String方式。省去了我们自定义RedisTemplate的过程:
@SpringBootTest
class RedisStringTest {
@Autowired
StringRedisTemplate stringRedisTemplate;
/**
* Spring中默认的json序列化工具
*/
private static final ObjectMapper objectMapper = new ObjectMapper();
@Test
void test() throws JsonProcessingException {
User user = new User();
user.setName("赖卓成");
user.setAge(24);
user.setAddress("广东深圳");
// 手动序列化并存储
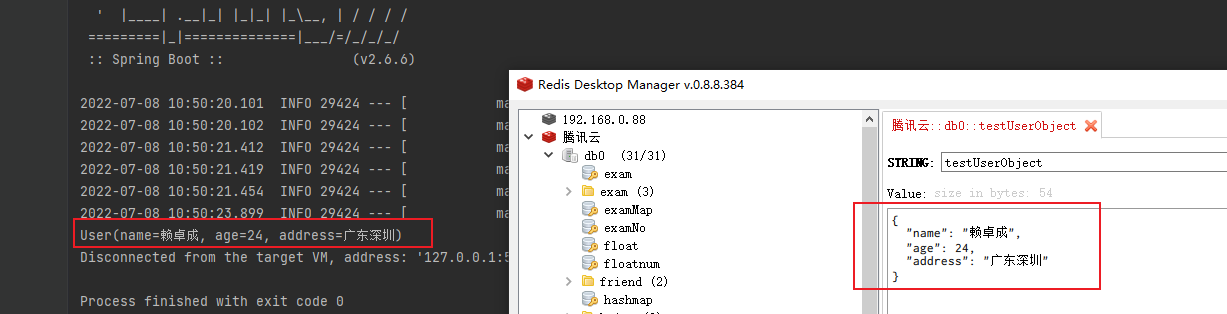
stringRedisTemplate.opsForValue().set("testUserObject", objectMapper.writeValueAsString(user));
String jsonStr = stringRedisTemplate.opsForValue().get("testUserObject");
// 手动反序列化
User redisUser = objectMapper.readValue(jsonStr, User.class);
System.out.println(redisUser);
}
}
运行结果可以看到,手动序列化后的数据没有带class路径了:
Redis的两种序列化方案:
方案一:
- 自定义RedisTemplate
- 修改RedisTemplate的value的序列化器为GenericJackson2JsonRedisSerializer
方案二:
- 使用StringRedisTemplate
- 写入Redis时,手动把对象序列化为Json
- 读取Redis时,手动把读取到的JSON反序列化为对象
方案三(参考了公司的代码):
方案一中的GenericJackson2JsonRedisSerializer换成Jackson2JsonRedisSerializer
GenericJackson2JsonRedisSerializer和Jackson2JsonRedisSerializer的区别
p23-RedisTemplate操作Hash类型
需要注意的是官方命令是hset,但是在Java中使用的是put方法。其他方法也是接近于Java的方法。举例:
@Test
void testHash(){
stringRedisTemplate.opsForHash().put("testHash", "name", "赖卓成");
stringRedisTemplate.opsForHash().put("testHash", "age", "24");
stringRedisTemplate.opsForHash().put("testHash", "address", "广东深圳");
String name = (String) stringRedisTemplate.opsForHash().get("testHash", "name");
System.out.println(name);
String age = (String) stringRedisTemplate.opsForHash().get("testHash", "age");
System.out.println(age);
String address = (String) stringRedisTemplate.opsForHash().get("testHash", "address");
System.out.println(address);
stringRedisTemplate.opsForHash().keys("testHash").forEach(key -> {
System.out.println(key);
});
stringRedisTemplate.opsForHash().values("testHash").forEach(value -> {
System.out.println(value);
});
Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("testHash");
entries.forEach((key, value) -> {
System.out.println(key + ":" + value);
});
}
}
运行结果:

实战篇
p25-导入项目
在资料在中导入项目,后端不使用微服务、前端在服务器nginx部署即可,导入数据库,修改配置信息,前后端项目启动后如下:
在服务器Nginx配置中加入server
server {
listen 8080;
server_name localhost;
# 指定前端项目所在的位置
location / {
root hmdp/hmdp;
index index.html index.htm;
}
}
修改common.js中的commonURL为本地地址,即可服务器加载页面,调用本地接口。
此时会出现CORS error,需要在后端项目中配置跨域:
/**
* 跨域配置
*
* @author lzc
* @date 2022/07/11
*/
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
//设置允许跨域的路径
registry.addMapping("/**")
.allowedOrigins("*")
//是否允许证书
.allowCredentials(true)
//设置允许的方法
.allowedMethods("GET", "POST")
//设置允许的header属性
.allowedHeaders("*")
//允许跨域时间
.maxAge(3600);
}
}
nginx配置中http加入允许跨域:
#support cross domain access
add_header Access-Control-Allow-Origin *;
add_header Access-Control-Allow-Headers X-Requested-With;
add_header Access-Control-Allow-Methods GET,POST,OPTIONS;
{% gi 2%}
{% endgi %}
项目中没有任何东西,只有基础的redis、MySQL、Mybatis-Puls、hutool、lombok依赖和对应的控制层、业务层、持久层类、以及工具类。
p26-基于session实现登录
知识点:ThreadLocal
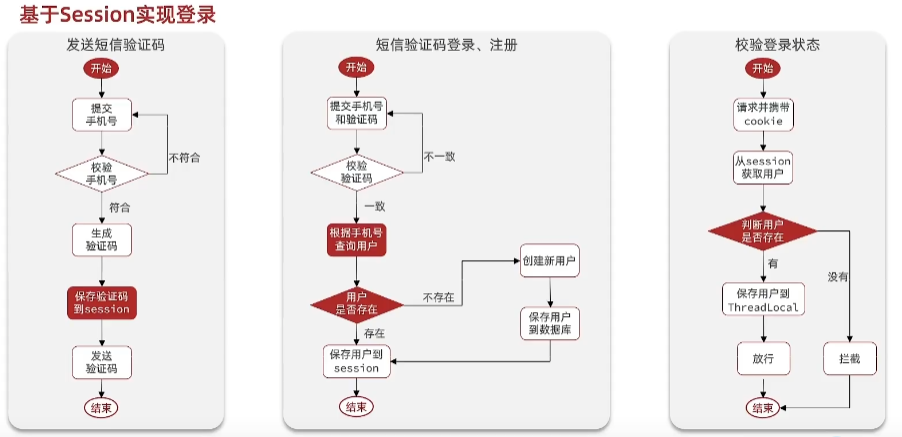
p-27实现验证码发送功能
控制层代码:
/**
* 发送手机验证码
*/
@PostMapping("code")
public Result sendCode(@RequestParam("phone") String phone, HttpSession session) {
return userService.sendCode(phone, session);
}
业务层代码:
@Override
public Result sendCode(String phone, HttpSession session) {
// 正则工具校验手机号是否合法
if (RegexUtils.isPhoneInvalid(phone)) {
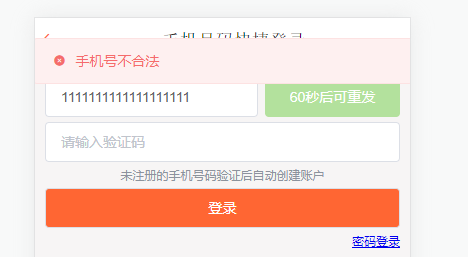
// 手机号不合法,返回错误信息
return Result.fail("手机号不合法");
}
// 手机号合法,hutool工具生成并发送验证码,模拟发送
String code = RandomUtil.randomNumbers(6);
log.info("发送验证码:{}", code);
// 将验证码存入session,用于校验
session.setAttribute("code", code);
return Result.ok("发送成功");
}
效果:

p28-实现短信登录和注册用户功能
- 用户请求过来,通过jsessionId可以获取到用户会话
- 从会话中取出验证码code
- 校验手机号是否合法、是否一致(此处未做,要做可以在发送验证码时加入手机号到session中)、
- 校验验证码是否正确,不正确直接抛出异常
- 验证码正确,查询用户是否存在,存在则直接登录,将用户信息存入session中
- 不存在则创建用户,将用户信息存入session中
@Override
public Result login(LoginFormDTO loginForm, HttpSession session) {
// 1 获取session中的验证码
String code = (String) session.getAttribute("code");
// 2 正则工具校验手机号是否合法,此处不做手机号是否一致的校验了
String phone = loginForm.getPhone();
if (RegexUtils.isPhoneInvalid(phone)) {
// 手机号不合法,返回错误信息
return Result.fail("手机号不合法");
}
// 3 判断验证码是否正确
if (code == null || !code.equals(loginForm.getCode())) {
// 验证码不正确,返回错误信息
return Result.fail("验证码不正确");
}
// 4 验证码正确,根据手机号查询用户信息
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>().eq(User::getPhone, loginForm.getPhone());
User user = baseMapper.selectOne(wrapper);
// 5 判断用户是否存在
if (null==user){
// 用户不存在,注册
user = createUserByPhone(phone);
}
// 6 保存用户到session中
session.setAttribute("user", user);
// 7 返回登录成功信息,此处不需要返回登录凭证,因为是session登录,用户cookie中已经有JSessionId
return Result.ok(user);
}
/**
* 创建用户
*
* @param phone 电话
* @return {@link User}
*/
private User createUserByPhone(String phone) {
User regUser = new User();
regUser.setCreateTime(LocalDateTime.now());
regUser.setUpdateTime(LocalDateTime.now());
// 雪花算法生成id
regUser.setId(new SnowflakeGenerator().next());
// 用户前缀+随机字符串生成用户名
regUser.setNickName(SystemConstants.USER_NICK_NAME_PREFIX +RandomUtil.randomString(6));
regUser.setPhone(phone);
return regUser;
}
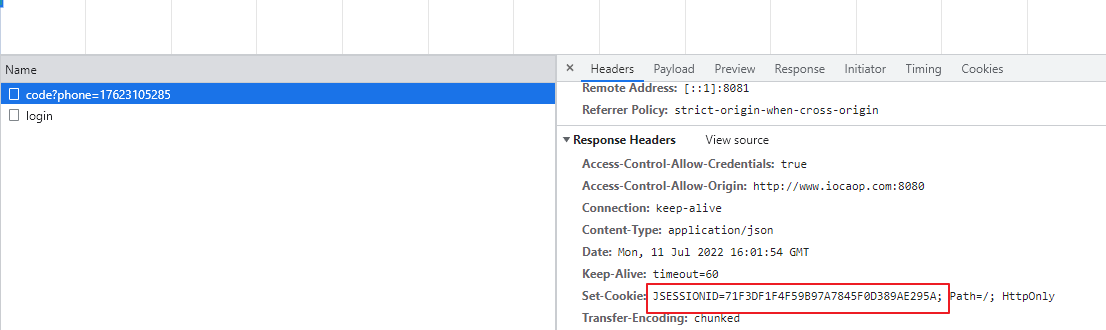
此处遇到一个问题,浏览器每次访问,JSessionId都在变化:
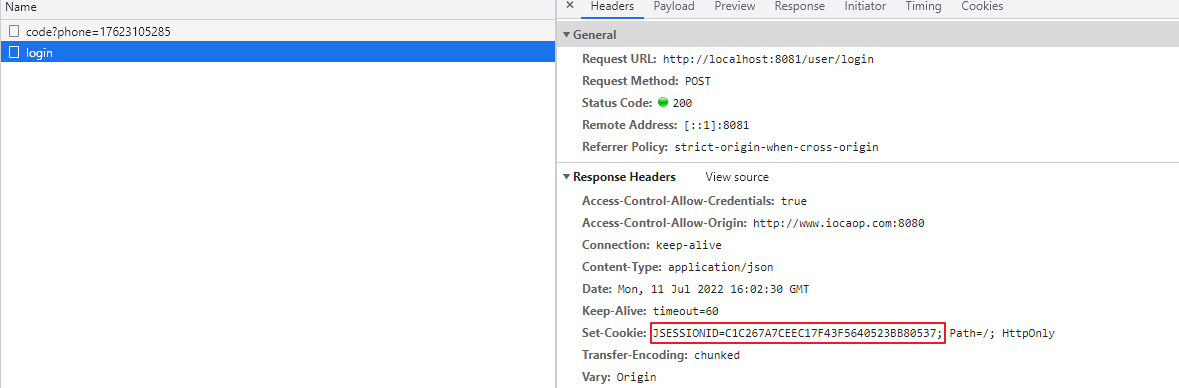
解决:
这种情况有三种可能
- 分布式环境下,session不一致(排除)
- 未设置cookie允许跨域(设置后,JSessionId依然在变)
- 跨域请求不允许携带Cookie跨域请求无法携带Cookie的问题(配置后依然无效)
该问题无法解决,意义也不大,跳过p29、p30
p31-session共享的问题分析
为了提升项目并发,单体项目一般会部署多个服务,运行多个Tomcat,采用nginx进行负载均衡,那么问题是这多台Tomcat的session不共享,会导致信息丢失。
比如验证码登录问题,当一个请求第一台服务器,进行获取短信,Tomcat1生成的验证码是9527发给了用户,当用户登录请求进来,携带了验证码9527到Tomcat2,由于session不共享,Tomcat2的code为null,导致验证码错误,登录失败,这显然是不合理的。
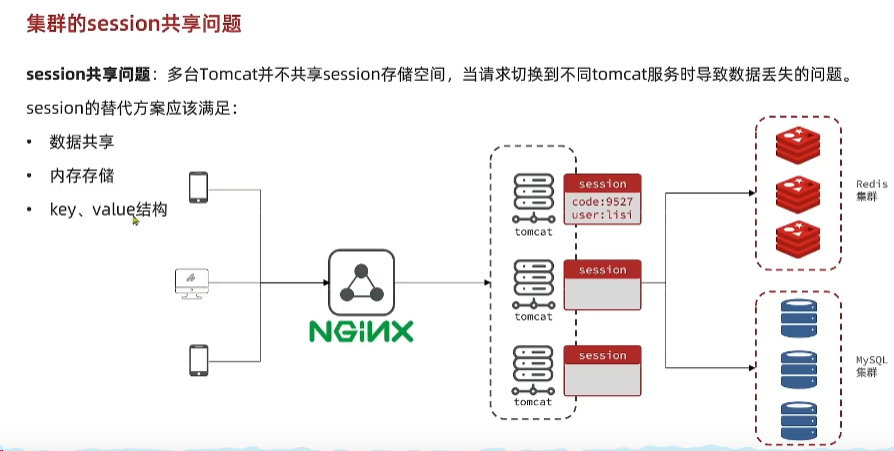
Tomcat提供了session拷贝的功能,只需要配置好就行,但是存在问题:
- 多台Tomcat相同的数据,却需要互相拷贝,内存浪费
- 数据拷贝会有延迟,实时性不高,若在拷贝前有请求,则会出问题。
session的替代方案应该满足:
- 数据共享
- 内存存储(读写速度快)
- k-v结构(方便)
Redis可以解决这个问题:
- 任何Tomcat可以访问Redis、
- 基于内存存储,Redis读写延迟是微秒级别的,
- k-v存储。
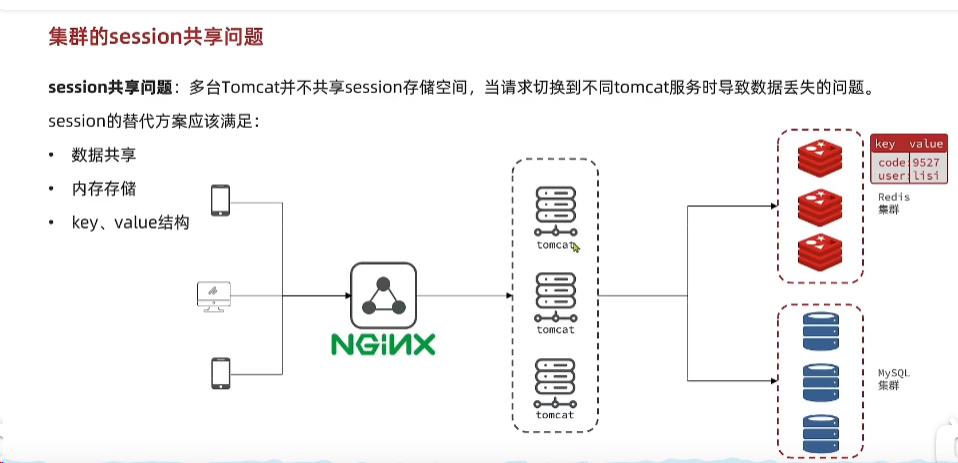
p32-Redis代替Session的业务流程
使用手机号(唯一的即可,客户端方便携带,利于取,最好是用随机字符串)作为key,valuevalue存储用户的信息,可以是用户对象。,可以用String类型,也可以用Hash类型。
二者对比:
String需要序列化对象再存储,会更直观,但是会多出很多字符,双引号,大括号等。
Hash存储更方便修改对象中的字段,而且会更节省内存空间。
使用token(或随机字符串)作为key,客户端下次再携带这个token来访问,服务器可以根据token取数据,判断用户是否登录,之前是因为cookie中携带了JsessionId,访问时Tomcat会根据JsessionId获取session。现在不需要这样了,我们把token手动setCookie到浏览器或sessionStorage即可, 浏览器访问会携带上token。