java基础-多线程
11-1-多线程
01-初步了解多线程
指从软件或者硬件上实现多个线程并发执行的技术。
具有多线程能力的计算机因为有硬件支持而能够在同一时间执行多个线程,提升性能。
02-并发和并行
- 并行:在同一时刻,有多个指令在多个cpu上同时执行。
- 并发:在同一时刻,有多个指令在单个cpu上交替执行。
03-进程和线程
进程:正在运行的软件。最直观的,直接看任务管理器。
进程的特点:
- 独立性:进程是一个能独立运行的基本单位,也是系统分配资源和调度的独立单位。
- 动态性:进程实质是程序的一次执行过程,进程是动态产生动态消亡的。
- 并发性:任何进程都可以同其他进程一起并发执行。
线程:是进程中的单个顺序控制流,是一条执行路径。
简单来说,火绒是一个进程,里面的垃圾清理,病毒查杀等功能,是火绒这个进程下的线程,他们可以同时执行。
- 单线程:一个进程如果只有一条执行路径,则称为单线程程序。
- 多线程:一个进程如果有多条执行路径,则称为多线程程序。
04~07-多线程的实现方式
先学三种实现方式:
继承
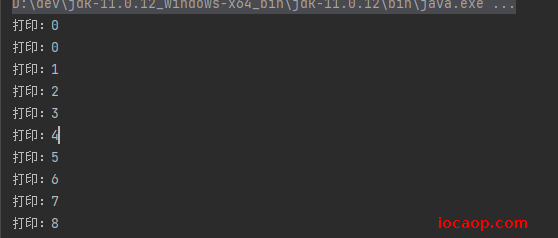
Thread类public class MyThread extends Thread{ @Override public void run() { // 自定义一个类,重写run方法,线程开启后,就会执行run方法 for (int i = 0; i < 100; i++) { System.out.println("打印:"+i); } } }public class MyThreadRunDemo { public static void main(String[] args) { // 创建两个线程对象 MyThread t1 = new MyThread(); MyThread t2 = new MyThread(); // 用start方法开启线程 t1.start(); t2.start(); } }看结果可以知道,这两条线程是并发执行的,并且由于cpu上下文切换的随机性,每次运行结果可能都不一样。
为什么要重写run方法?因为线程执行以后,要执行run方法,run方法是用来封装线程需要执行的代码用的。
run方法和start方法的区别?通过打印线程名称或者id可以得出,调用run方法是由调用的线程执行的,并没有开启新的方法。而start方法是新开一个线程去执行,开启新线程的方法是由c++实现的,在Java中属于本地方法(native),源码中可以找到,方法名是start0。
实现
Runnable接口public class MyRunnableRunDemo { public static void main(String[] args) { MyRunnable runnable = new MyRunnable(); // 需要注意的时,runnable中没有start方法,需要将runnable对象作为参数,传递给Thread的构造,来启动线程 Thread t1 = new Thread(runnable); Thread t2 = new Thread(runnable); t1.start(); t2.start(); } }
Callable和Future接口实现public class MyCallable implements Callable<String> { /** * 和run方法一样,是线程执行代码的封装方法 * 返回值是实现Callable时所指定的泛型,这里是String,意味着线程执行call方法,返回结果也是String类型 * * @return {@link String} * @throws Exception 异常 */ @Override public String call() throws Exception { for (int i = 0; i < 100; i++) { System.out.println("打印:"+i); } return "call执行完毕"; } }public class MyCallableRunDemo { public static void main(String[] args) throws ExecutionException, InterruptedException { // 线程开启后,会调用该对象的call方法,执行封装好的代码 MyCallable myCallable = new MyCallable(); // 可以获取call方法的返回结果,同时作为参数传递给Thread的构造 FutureTask<String> futureTask = new FutureTask<>(myCallable); // 创建线程对象 Thread thread = new Thread(futureTask); // 开启线程 thread.start(); // 获取线程执行的结果 String s = futureTask.get(); System.out.println("线程执行的结果:"+s); } }为什么创建线程的时候不能直接传递
Callable实现类的对象呢?因为Thread的构造需要的是Runnable接口的实现类对象,而Callable没有实现Runnable接口,FutureTask实现了Runnable接口: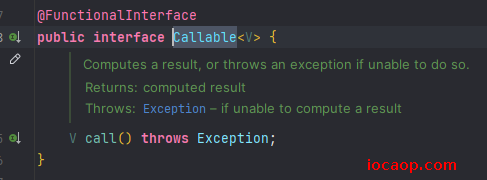
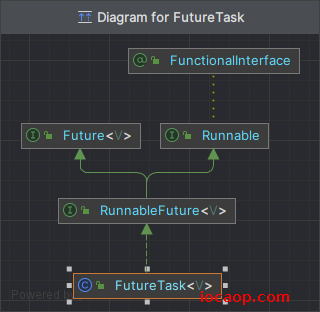
执行结果:

思考一个问题:如果在start()方法调用执行使用FutureTask的get()方法,会发生什么?
没有任何结果,但是main方法也没有停止。get()方法是获取线程执行的结果,如果线程还没有启动运行,那么get()方法会一直等着。
08-三种实现方式的对比

09-Thread方法-设置、获取线程名称
获取线程名称:
public class MyThread extends Thread{
@Override
public void run() {
for (int i = 0; i < 100; i++) {
// 调用Thread中继承过来的方法获取线程名称
System.out.println(super.getName()+"打印:"+i);
}
}
}
public class MyThreadDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
}
}
线程是有默认名字的,格式为Thread-编号,源码中可以看出:

设置线程名称:
方式1:调用set方法
public class MyThreadDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.setName("我的线程1");
myThread.start();
}
}
方式2:构造方法传入
public class MyThreadDemo {
public static void main(String[] args) {
MyThread myThread = new MyThread("我的线程1");
myThread.start();
}
}
public class MyThread extends Thread{
public MyThread(String name) {
super(name);
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
// 调用Thread中继承过来的方法获取线程名称
System.out.println(super.getName()+"打印:"+i);
}
}
}
10-Thread方法-获取当前线程对象
获取当前线程对象,当前线程是由哪个线程执行,就会返回哪个线程的对象。
11-Thread方法-sleep

让线程休眠,哪条线程执行到了这个方法,就会将哪条线程进行休眠,参数是休眠时间,单位是毫秒。
会抛出异常,处理异常的线程是调用线程(谁调用了Thread.sleep()这个异常就是谁处理)。
12-线程调度-线程的优先级
多线程的并发:
计算机中的cpu在任一时刻只能执行一条及其指令,每个线程只有获得cpu的使用权才能执行任务,各个线程轮流获得cpu的执行权,分别执行各自的任务。
两种调度模型:
分时调度模型:所有线程轮流使用cpu,平均分配每个线程占用cpu的时间片。
抢占式调度模型:优先让优先级高的线程使用cpu,优先级相同则随机,这样以来,优先级高的线程,获取cpu的时间片相对多一些。
Java中使用的是抢占式调度模型
Java中可以设置线程的优先级:Thread类的源码
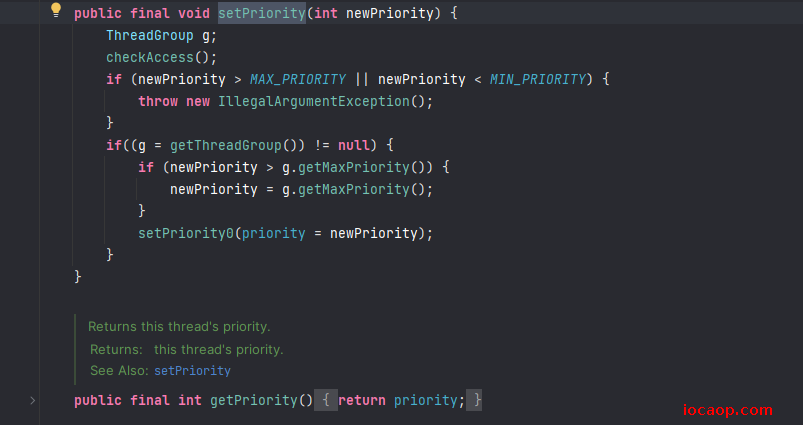
默认优先级是5,最大10,最小1。
线程优先级越高,只能说明他抢到cpu使用权的几率更高,不意味着他先执行。
13-Thread方法-守护线程
又叫后台线程。
普通线程执行完毕了,守护线程也会停止运行:Thread源码
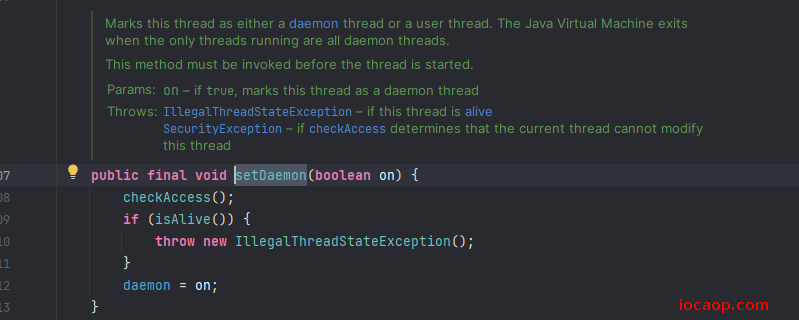
守护线程的意义是什么?守护普通线程
比如qq传文件,传到一般,我把整个qq退出了。那传输文件的线程就是守护线程,整个qq退出了,守护线程传文件就没必要存在了。
写个demo,普通线程循环打印10次,守护线程循环打印100次,普通线程打印完10次,守护线程会继续执行吗?
public class MyThread01 extends Thread{
@Override
public void run() {
super.setName("普通线程");
for (int i = 0; i < 10; i++) {
System.out.println(super.getName()+"---"+i);
}
}
}
public class MyThread02 extends Thread{
@Override
public void run() {
super.setName("守护线程");
for (int i = 0; i < 100; i++) {
System.out.println(super.getName()+"---"+i);
}
}
}
public class MyDaemonRunDemo {
public static void main(String[] args) {
MyThread01 myThread01 = new MyThread01();
MyThread02 myThread02 = new MyThread02();
// 设置为守护线程
myThread02.setDaemon(true);
myThread01.start();
myThread02.start();
}
}
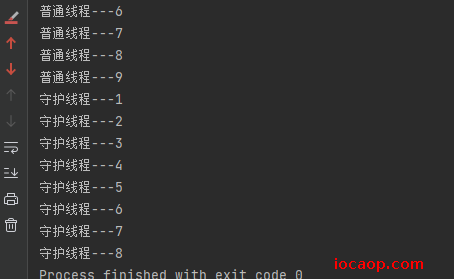
结果可以看出,当普通线程执行完毕后,守护线程并不会继续执行了。但也不会马上停止,因为他还占用着cpu,要过一会再停止。
11-2线程安全问题
14-卖票案例实现
多个线程同时操作共享资源,就会有线程安全问题。
需求:某电影院上映国产大片,一共100张票,有3个卖票窗口,编程模拟卖票。
思路:实现Runnable接口,run方法卖票,成员变量表示余票。三个窗口线程使用相同的Runnable对象,保证100张票是共享的。
public class Ticket implements Runnable{
private Integer count=100;
@Override
public void run() {
while (true){
if (count<=0){
throw new RuntimeException("卖完啦");
}
this.count--;
System.out.println(Thread.currentThread().getName()+"卖出一张票,还剩:"+this.count+"张");
}
}
}
public class MyTicketRunDemo {
public static void main(String[] args) {
Ticket ticket = new Ticket();
Thread t1 = new Thread(ticket);
Thread t2 = new Thread(ticket);
Thread t3 = new Thread(ticket);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
运行:
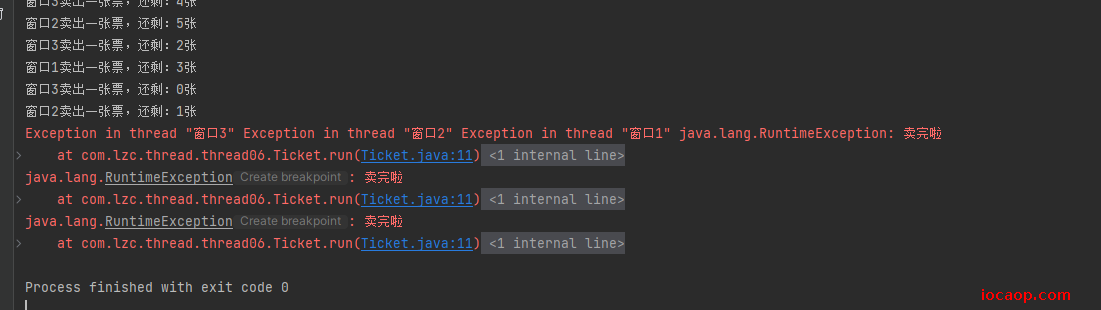
结合我所学的知识,已经看出问题,在抛出异常的if这里,cpu执行时,if并不是一条指令,会被编译成多条指令,有一种可能,当售票到最后一张票(不是最后一张也行,Redis的自增自减是原子操作,java中的i--不是原子操作,点击跳转,一样会超卖),当判断指令(jcc指令)刚走完,还没来得及自减,cpu就调度了,执行另一个线程的指令了,此时count会被多个线程自减多次即使他已经小于等于0了(因为判断已经走完了),导致超卖。
15-卖票案例并发问题原因分析
结合生活实际,售票出票需要时间,我们给线程加点延迟,每次出票时间是100毫秒,即每次自减,睡眠100毫秒,看看会怎么样?
public class Ticket implements Runnable{
private Integer count=100;
@Override
public void run() {
while (true){
if (count<=0){
throw new RuntimeException("卖完啦");
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.count--;
System.out.println(Thread.currentThread().getName()+"卖出一张票,还剩:"+this.count+"张");
}
}
}
看结果:出现了负数
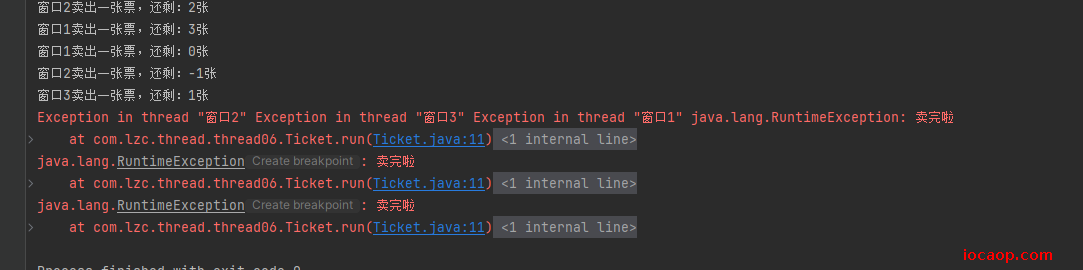
情况1:重复票
线程1执行到打印语句之前是99,切到线程2,又走到打印语句前是98,切到线程3,又走到打印语句前是97,这是线程1、线程2、线程3都走打印语句。打出来三个都是97.重复票。
情况2:超卖,负号票
和我上面14节课说的一样,线程1、线程2、线程3都走到自减之前,cpu调度了,导致超卖。
16-同步代码块
我们看看,操作共享数据的代码是哪块:从判断语句就开始了,直到打印语句。
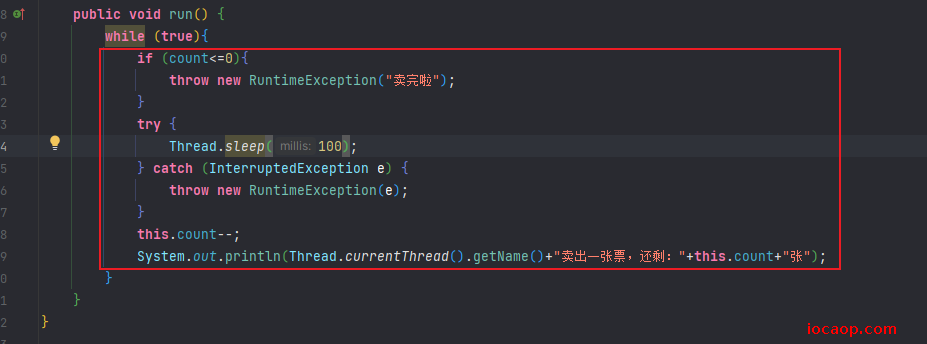
思考:如果操作共享数据时,只让一条线程操作,等这条数据操作完了,其他线程再操作,是不是就解决了上面的两个问题?
为什么出现问题?
多线程操作共享数据
如何解决多线程安全问题?
基本思想:让程序没有安全问题的环境
怎么实现?
多条语句操作共享数据的代码锁起来,让任意时刻只能有一个线程执行。
同步代码块:
synchronized(任意对象){多条语句操作共享数据的代码}
默认情况,这个锁是打开的,只要有一个线程进去执行代码了,锁就会关闭。当线程执行完毕出来了,锁才会自动打开。
锁的好处和弊端:
好处是解决了多线程的数据安全问题。
坏处是影响性能,线程很多,都会访问同步上的锁,耗费资源。
实现:修改run方法,加锁。
@Override
public void run() {
while (true){
synchronized (this){
if (count<=0){
throw new RuntimeException("卖完啦");
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.count--;
System.out.println(Thread.currentThread().getName()+"卖出一张票,还剩:"+this.count+"张");
}
}
}
加锁后运行,不会出现重复票和负号票:
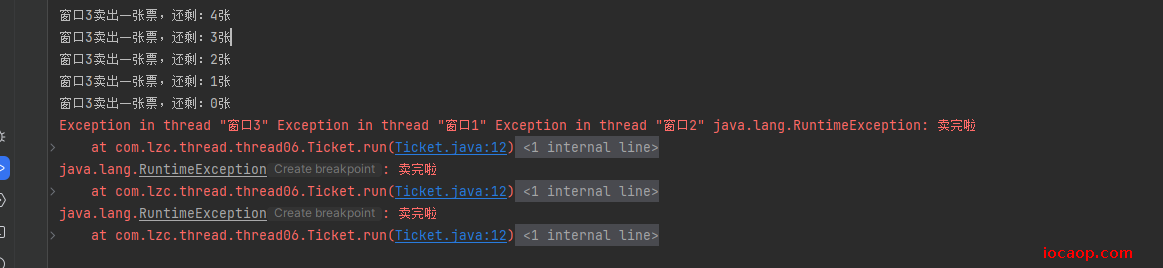
17-锁对象的唯一
将上面的卖票案例改写,不使用Runnable,而是直接继承Thread类:
public class TicketThread extends Thread{
private Integer count=100;
@Override
public void run() {
while (true){
synchronized (this){
if (count<=0){
throw new RuntimeException("卖完啦");
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
this.count--;
System.out.println(Thread.currentThread().getName()+"卖出一张票,还剩:"+this.count+"张");
}
}
}
}
public class MyTicketRunDemo {
public static void main(String[] args) {
Thread t1 = new TicketThread();
Thread t2 = new TicketThread();
Thread t3 = new TicketThread();
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
运行发现,每张票都是重复票,原因:count不是共享数据,需要加static:
private static Integer count=100;
修改后运行发现:出现负号票,原因,锁不是唯一的,使用的是this,是线程对象,三个窗口各自有各自的对象,锁不唯一

将锁改为唯一的:
synchronized (this.getClass())
运行结果正常:
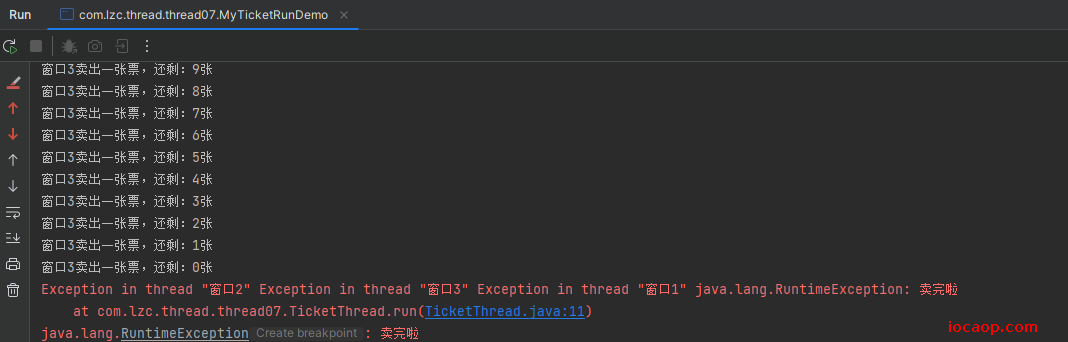
18-同步方法
同步方法:就是把synchronized关键字加到方法上。
格式:
修饰符 synchronized 返回值类型 方法名(方法参数){}
同步代码块和同步方法的区别:
- 同步代码块是锁住指定的方法,同步方法是锁住方法中所有的代码。
- 同步代码块可以指定锁对象,同步方法不能指定锁对象。
同步方法的锁对象是谁?是this。
将上面的售票案例,改为窗口1使用同步方法,窗口2使用同步代码块:
/**
* 同步方法和同步代码块
*
* @author 赖卓成
* @date 2023/06/21
*/
public class MyRunnable implements Runnable {
public static int count = 100;
@Override
public void run() {
while (true) {
if ("窗口1".equals(Thread.currentThread().getName())) {
boolean empty = this.syncMethod();
if (empty) {
break;
}
}
if ("窗口2".equals(Thread.currentThread().getName())) {
// 同步代码块
synchronized (new Object()) {
if (count <= 0) {
break;
}
try {
Thread.sleep(100L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
count--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,还剩:" + count + "张");
}
}
}
}
/**
* 同步方法
*
* @return boolean
*/
private synchronized boolean syncMethod() {
if (count <= 0) {
return true;
}
try {
Thread.sleep(100L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
count--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,还剩:" + count + "张");
return false;
}
}
/**
* 同步方法和同步代码块
*
* @author 赖卓成
* @date 2023/06/21
*/
public class MyRunnableRunDemo {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread t1 = new Thread(myRunnable);
Thread t2 = new Thread(myRunnable);
t1.setName("窗口1");
t2.setName("窗口2");
t1.start();
t2.start();
}
}
19-Lock
上面两节使用了synchronized,同步方法和同步代码块。我们可以理解他加了锁,但是却看不到他在哪里加了锁,哪里释放了锁,为了更清楚地表达如何加锁、释放锁,jdk5以后提供了一个新的锁对象Lock。
Lock提供了比使用synchronized方法和语句可以获得更广泛的锁定操作。
- void lock():获得锁
- void unlock():释放锁
Lock是接口,不能直接实例化,这里才用它的实现类ReentrantLock来实例化。
这里先简单使用一下ReentrantLock,改写之前的售票案例:
public class TicketThread extends Thread {
private static Integer count = 100;
/**
* 为了多个线程使用同一把锁,需要将锁定义为静态变量
*/
private static ReentrantLock lock = new ReentrantLock();
@Override
public void run() {
while (true) {
lock.lock();
if (count <= 0) {
throw new RuntimeException("卖完啦");
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
count--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,还剩:" + count + "张");
lock.unlock();
}
}
}
public class MyTicketRunDemo {
public static void main(String[] args) {
Thread t1 = new TicketThread();
Thread t2 = new TicketThread();
Thread t3 = new TicketThread();
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
运行结果正确:
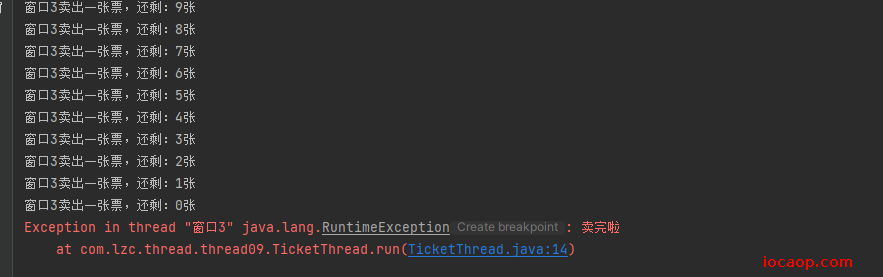
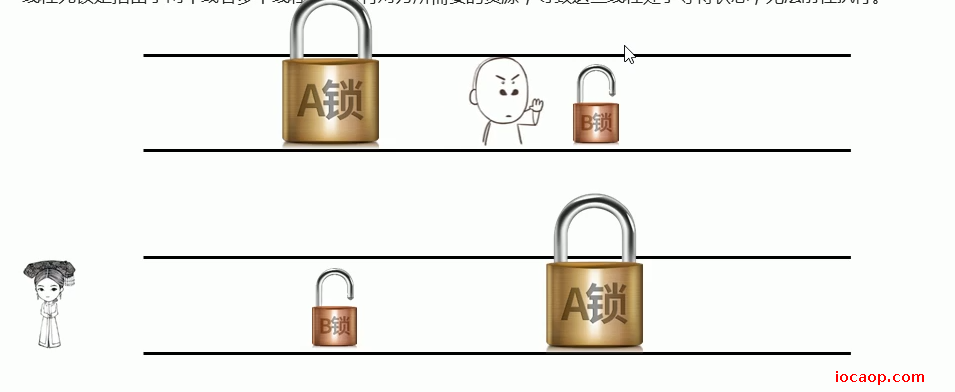
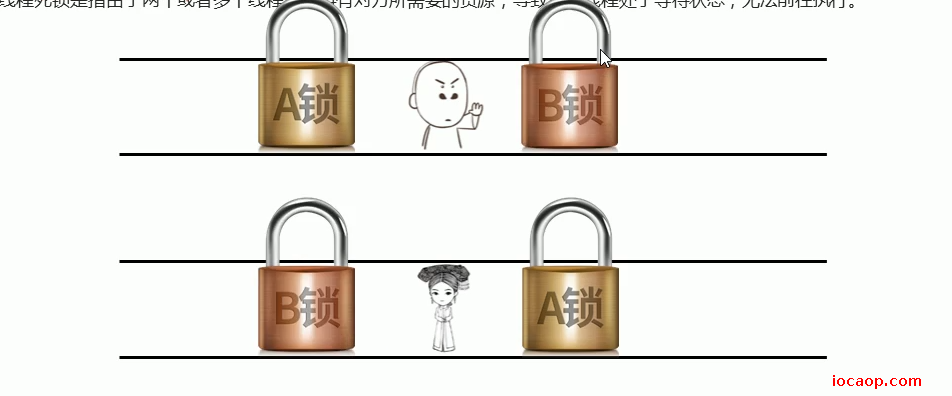
20-死锁
死锁是指两个或多个线程相互持有对方所需要的资源,导致这些资源处于等待状态,无法继续往前执行。
课程中的例子:
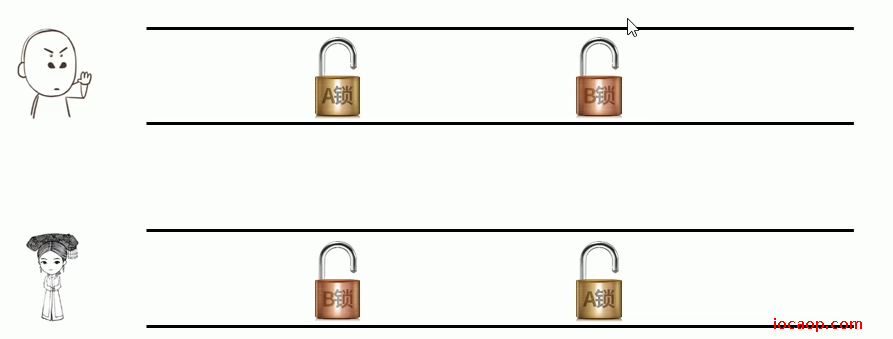
代码实现:
/**
* 死锁
*
* @author lzc
* @date 2023/06/26
*/
public class DeadLock {
public static void main(String[] args) {
// 创建两把锁
Object lockA = new Object();
Object lockB = new Object();
new Thread(()->{
while (true){
synchronized (lockA){
synchronized (lockB){
System.out.println(new Date()+"线程1获取了两把锁");
}
}
}
}).start();
new Thread(()->{
while (true){
synchronized (lockB){
synchronized (lockA){
System.out.println(new Date()+"线程2获取了两把锁");
}
}
}
}).start();
}
}
线程1先获取锁A,再获取锁B。线程2先获取锁B,再获取锁A。
有一种情况,就是线程1获取锁A或,cpu切换到线程2,线程2获取了锁B,导致线程1无法获取锁B,而线程2需要的锁A又被线程1获取了。两个线程互相等待,导致死锁。打印了一段时间后,就不再打印了,但是程序没有停止。
如何解决?不要嵌套使用锁就好了。
11-3-生产者和消费者
21-思路分析
生产者生产出来的东西,给消费者消费。课程中的例子:厨师生产汉堡,放到桌子上,吃货来吃。

吃货线程和厨师线程需要轮流执行。
厨师:
- 判断桌子上是否有汉堡,有则等待,没有则生产
- 把汉堡放桌上
- 叫醒吃货吃汉堡
吃货:
- 判断桌子上是否有汉堡
- 没有则等待
- 如果有就吃
- 吃完后,桌上没了
- 叫醒等待的厨师继续生产
22-代码实现
为了体现生产和消费过程的等待和唤醒,Java在Object类提供了方法:

/**
* 厨师线程
*
* @author lzc
* @date 2023/06/26
*/
public class Cooker extends Thread {
@Override
public void run() {
// 死循环
while (true) {
// 获取锁
synchronized (Desk.lock) {
// 是否生产够了10个
if (Desk.count <= 0) {
break;
}
// 桌子上是否有汉堡
if (Desk.flag) {
// 有则等待
try {
Desk.lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
} else {
// 没有则生产,将标志设置为有
Desk.flag = true;
// 生产者这里不处理count了,在消费者处理一次即可。
System.out.println("厨师已经生产了第" + (1001 - Desk.count) + "个汉堡!");
// 通知吃货来吃,这里我们只开启了一个吃货和一个厨师,所以不使用notifyAll()
Desk.lock.notify();
}
}
}
}
}
/**
* 吃货线程
*
* @author lzc
* @date 2023/06/26
*/
public class Foodie extends Thread {
@Override
public void run() {
// 死循环
while (true) {
// 获取锁
synchronized (Desk.lock) {
// 吃够了10个没有
if (Desk.count <= 0) {
break;
}
// 桌子上是否有汉堡
if (Desk.flag) {
// 有则吃
System.out.println("吃货吃完了第" + (1001 - Desk.count) + "个汉堡");
// 数量减1
Desk.count--;
// 修改标记
Desk.flag = false;
// 通知厨师生产汉堡
Desk.lock.notify();
} else {
//没有汉堡则等待,需要注意的是,这里调用wait方法的锁,需要生产者和消费者是同一把锁,也就是同一个对象去调用
try {
Desk.lock.wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
}
}
/**
* 桌子
*
* @author lzc
* @date 2023/06/26
*/
public class Desk {
/**
* 汉堡数量
*/
public static int count = 1000;
/**
* 锁
*/
public static Object lock = new Object();
/**
* 标志、桌子上是否有汉堡
*/
public static boolean flag = false;
public static void main(String[] args) {
Cooker cooker = new Cooker();
Foodie foodie = new Foodie();
cooker.start();
foodie.start();
}
}
运行结果:无论设置数量为多少,都是交替执行。

需要注意,厨师生产完或吃货吃完,都需要调用使用锁对象调用
notify()方法来通知其他线程。
23-代码改写
上面代码用的是简单的方式,我们改写一下,面向对象。
/**
* 桌子
*
* @author lzc
* @date 2023/06/26
*/
@Data
@AllArgsConstructor
public class Desk {
/**
* 汉堡数量
*/
private int count = 1000;
/**
* 锁
*/
private Object lock = new Object();
/**
* 标志、桌子上是否有汉堡
*/
private boolean flag = false;
}
/**
* 厨师线程
*
* @author lzc
* @date 2023/06/26
*/
@AllArgsConstructor
public class Cooker extends Thread {
private Desk desk;
@Override
public void run() {
// 死循环
while (true) {
// 获取锁
synchronized (this.desk.getLock()) {
// 是否生产够了10个
if (this.desk.getCount()<= 0) {
break;
}
// 桌子上是否有汉堡
if (this.desk.isFlag()) {
// 有则等待
try {
this.desk.getLock().wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
} else {
// 没有则生产,将标志设置为有
this.desk.setFlag(true);
// 生产者这里不处理count了,在消费者处理一次即可。
System.out.println("厨师已经生产了第" + (1001 - this.desk.getCount()) + "个汉堡!");
// 通知吃货来吃,这里我们只开启了一个吃货和一个厨师,所以不使用notifyAll()
this.desk.getLock().notify();
}
}
}
}
}
/**
* 吃货线程
*
* @author lzc
* @date 2023/06/26
*/
@AllArgsConstructor
public class Foodie extends Thread {
private Desk desk;
@Override
public void run() {
// 死循环
while (true) {
// 获取锁
synchronized (this.desk.getLock()) {
// 吃够了10个没有
if (this.desk.getCount() <= 0) {
break;
}
// 桌子上是否有汉堡
if (this.desk.isFlag()) {
// 有则吃
System.out.println("吃货吃完了第" + (1001 - this.desk.getCount()) + "个汉堡");
// 数量减1
this.desk.setCount(this.desk.getCount()-1);
// 修改标记
this.desk.setFlag(false);
// 通知厨师生产汉堡
this.desk.getLock().notify();
} else {
//没有汉堡则等待,需要注意的是,这里调用wait方法的锁,需要生产者和消费者是同一把锁,也就是同一个对象去调用
try {
this.desk.getLock().wait();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
}
}
public class Demo {
public static void main(String[] args) {
Desk desk = new Desk(1000, new Object(), false);
Cooker cooker = new Cooker(desk);
Foodie foodie = new Foodie(desk);
cooker.start();
foodie.start();
}
}
24-阻塞队列-基本使用
阻塞队列实现等待唤醒机制。
还是上面的生产者消费者案例,只不过消费者消费时,是从阻塞队列中拿,如果有,就拿一个来消费,没有就等待

阻塞队列的继承结构:
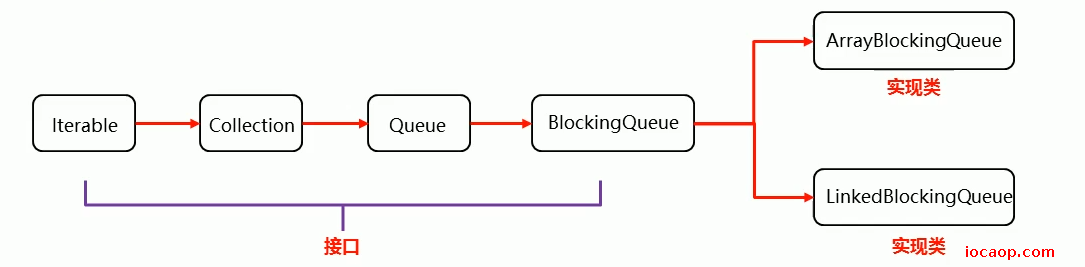
常见的BlockingQueue:
ArrayBlockingQueue:底层是数组,有界
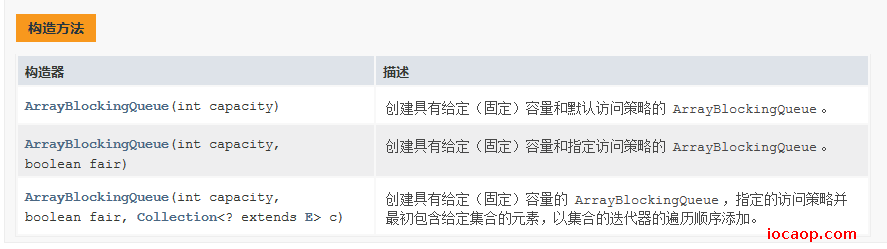
/** * 阻塞队列demo01 * * @author lzc * @date 2023/06/27 */ public class BlockingQueueDemo01 { public static void main(String[] args) { ArrayBlockingQueue<String> arrayBlockingQueue = new ArrayBlockingQueue<>(1); try { arrayBlockingQueue.put("汉堡包"); System.out.println("arrayBlockingQueue.take() = " + arrayBlockingQueue.take()); // 阻塞队列中只有一个元素,如果取两次,就会一直等待着,所以不会走到程序结束的代码 System.out.println("arrayBlockingQueue.take() = " + arrayBlockingQueue.take()); System.out.println("程序结束了"); } catch (InterruptedException e) { throw new RuntimeException(e); } } }一直等待,程序不会停止:
LinkedBlockingQueue:底层是链表,无界。但不是真正的无界,是int的最大值。
25-阻塞队列-等待唤醒机制
使用阻塞队列实现生产者消费者案例:
@AllArgsConstructor
public class Cooker extends Thread{
private ArrayBlockingQueue<String> blockingQueue;
@Override
public void run() {
while (true){
try {
this.blockingQueue.put("汉堡包");
System.out.println("厨师做好了一个汉堡包!");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
@AllArgsConstructor
public class Foodie extends Thread{
private ArrayBlockingQueue<String> blockingQueue;
@Override
public void run() {
while (true){
try {
String take = this.blockingQueue.take();
System.out.println("吃货吃掉了一个"+take);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class Demo {
public static void main(String[] args) {
ArrayBlockingQueue<String> arrayBlockingQueue = new ArrayBlockingQueue<>(1);
Cooker cooker = new Cooker(arrayBlockingQueue);
Foodie foodie = new Foodie(arrayBlockingQueue);
cooker.start();
foodie.start();
}
}
运行结果:
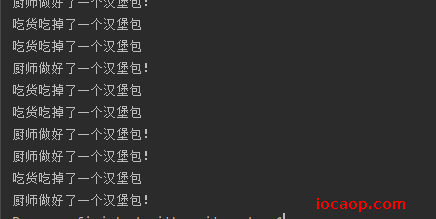
出乎意料,队列容量只有1,为什么会出现重复吃掉两个汉堡或者重复做了两个汉堡?
查看源码:
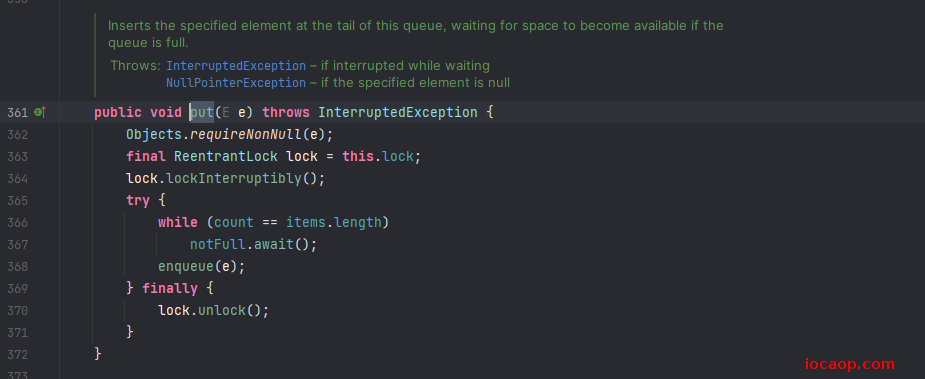
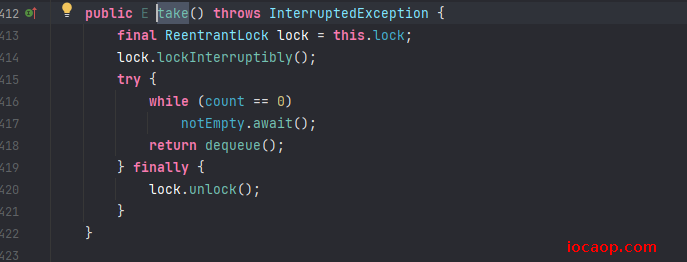
可以看出来,加锁的范围是put()和take(),我们手写的打印语句并不在加锁范围内。
简单说,就是吃货线程刚吃完一个,打印了一行,cpu切换到厨师线程,做好一个汉堡后,因为打印语句不在锁范围内,cpu可以切换到吃货线程,这时候队列已经有汉堡了,吃货又吃,打印了一行,导致连续打印两行,然后又切回到厨师线程,打印做好了。
gpt的回答:


11-4线程池和volatile
01-线程状态
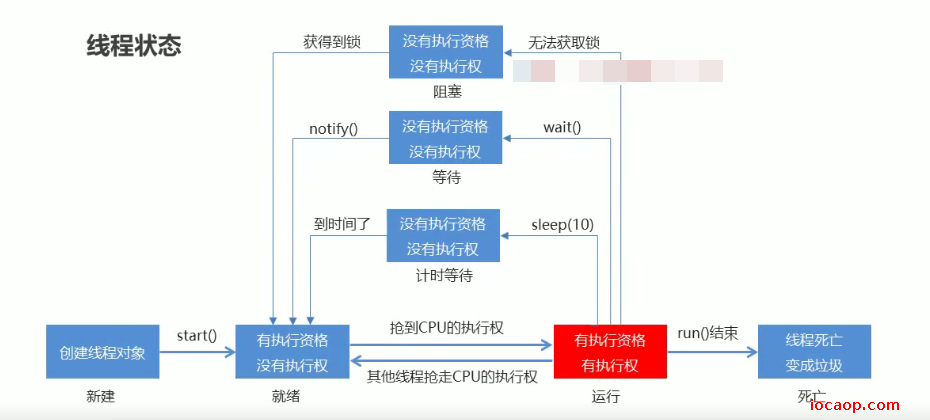
在虚拟机中,线程有六种状态:
- 新建状态(NEW):创建线程对象
- 就绪状态(RUNNABLE):线程对象调用
start()方法,这时候需要等待cpu时间片才会运行,虚拟机中没有定义运行状态。 - 阻塞状态(BLOCKED):无法获得锁对象
- 等待状态(WAITING):遇到
wait()方法 - 计时等待(TIMED_WAITING):遇到
sleep()方法 - 结束状态(TERMINATED):全部代码执行完毕
如何验证这六种状态?在Thread类中有枚举成员:

02-线程池-基本原理
以前写多线程的弊端:
- 用到线程时就需要创建
- 用完之后线程消失
解决方案:
- 创建线程池,用于存放线程,刚开始是空的
- 当有任务需要线程执行,则创建线程放到线程池,使用时取(看是否有空闲的线程,有则取,没有则创建新的),使用完后,将线程归还给线程池。
03-Executors默认线程池
创建线程池:
Executors中的静态方法有任务需要执行,创建线程对象,执行完,线程对象归还给线程池。:
submit()方法,会自动创建线程对象,任务执行完会自动归还给线程池。所有任务执行完,关闭线程池:
shutdown()方法。
看API,学习两个方法:

写个demo:
public class MyThreadPoolDemo01 {
public static void main(String[] args) {
// Executors帮助我们创建线程池对象,默认是空的,可以容纳int的最大值个线程
ExecutorService executorService = Executors.newCachedThreadPool();
// 返回值ExecutorService 可以帮助我们控制线程池
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"执行了");
});
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"执行了");
});
// 关闭线程池
executorService.shutdown();
}
}
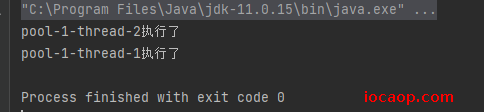
执行结果:
当修改代码:
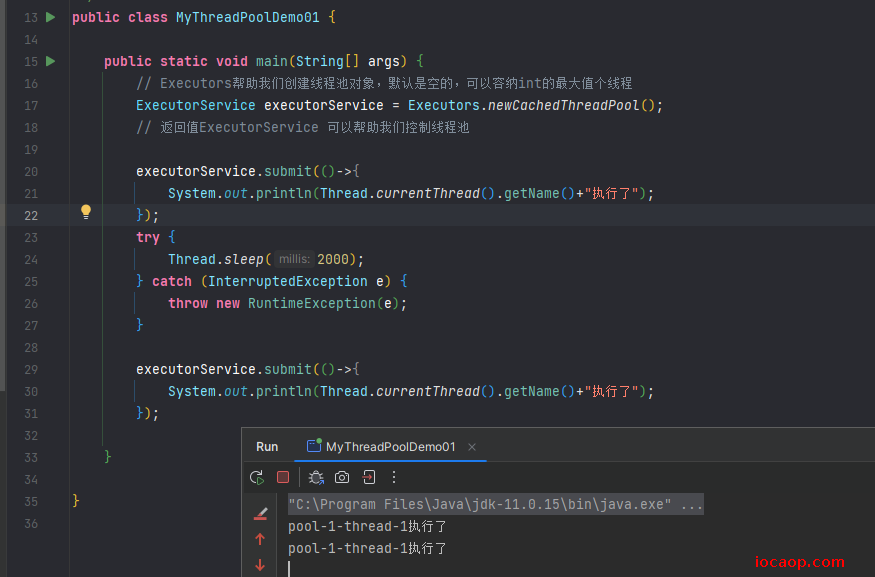
看到,只有一个线程了。
第一种结果是因为执行第一个任务时,还没来及归还线程给线程池,又执行第二个任务,所以会创建新的线程来执行。
第二种结果是主线程睡眠了2秒,线程池的第一个任务已经执行完了,将线程归还给了线程池,执行第二个任务时从线程池取了之前那个线程来执行。
05-Executors创建指定上限的线程池
/**
* 指定上限的线程池
*
* @author 赖卓成
* @date 2023/06/27
*/
public class MyThreadPoolDemo02 {
public static void main(String[] args) {
// 指定最大10个线程,而不是初始值
ExecutorService executorService = Executors.newFixedThreadPool(10);
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"执行了");
});
executorService.submit(()->{
System.out.println(Thread.currentThread().getName()+"执行了");
});
// 关闭线程池
executorService.shutdown();
}
}
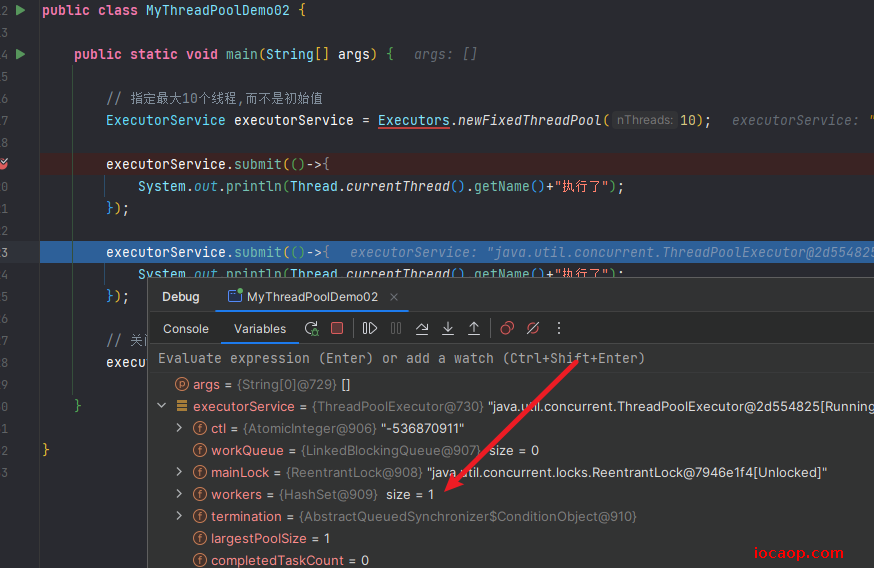
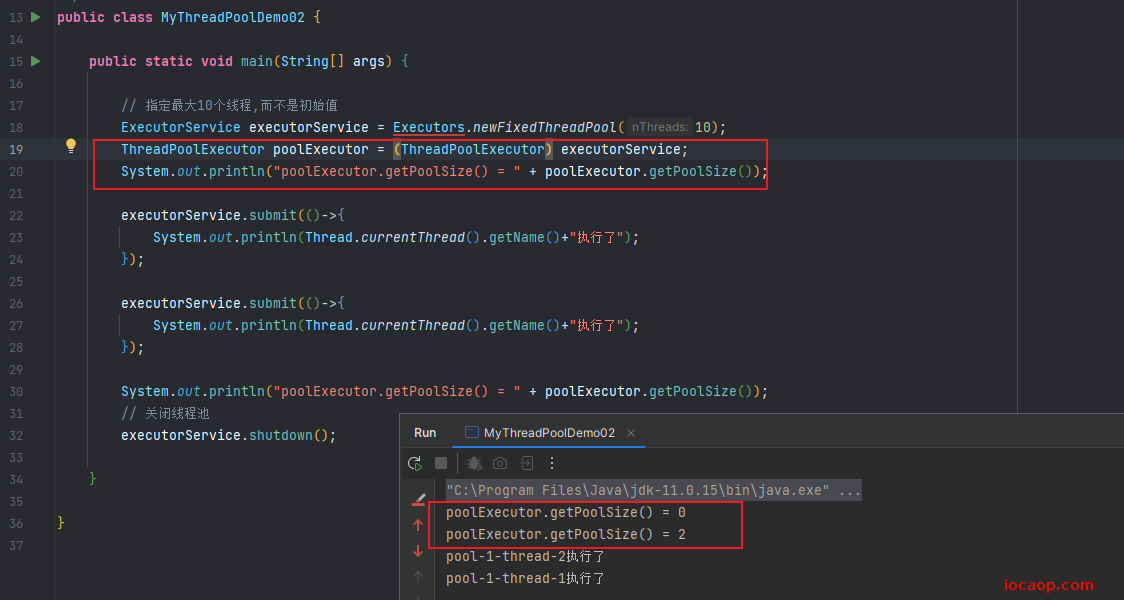
需要注意的是,我们传入的参数是指定线程池中的最大线程数,而不是初始线程数。
到这里,好像和上面的默认线程池没什么区别,但是,通过debug或者强转可以知道,这个线程池最大线程数被我们设置成10了,并不是初始线程数是10。
06-ThreadPoolExecutor
之前都是使用了默认的创建线程池的方法,那现在想要自定义创建线程池,怎么办?
先看看之前的方法的源码:


发现,都是创建了ThreadPoolExecutor
那么我们创建自定义线程池,也是创建这个对象。看一下API,构造方法:

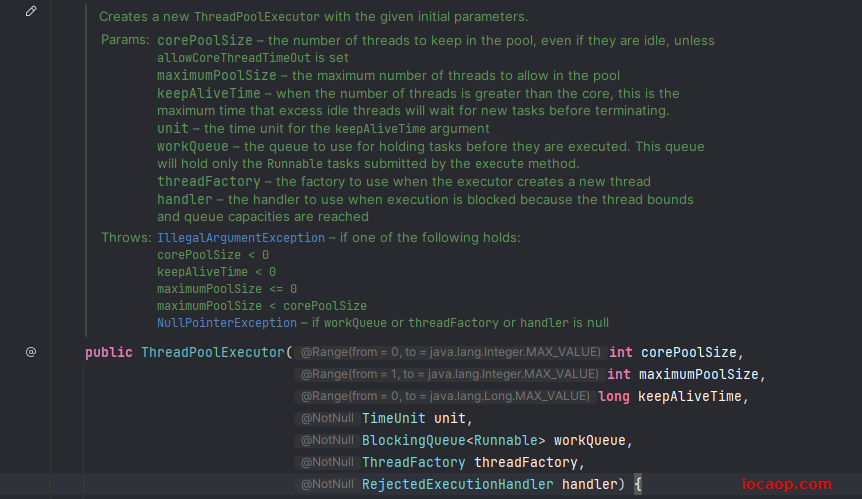
corePoolSize:核心线程数maximumPoolSize:最大线程数keepAliveTime:空闲线程的最大存活时间unit:空闲线程的最大存活时间的单位workQueue:任务队列threadFactory:创建线程的方式handler:拒绝策略
/**
* 自定义线程池
*
* @author 赖卓成
* @date 2023/06/27
*/
public class MyThreadPoolDemo03 {
public static void main(String[] args) {
// 自定义线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(2, 5, 10, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(), new AbortPolicy());
poolExecutor.submit(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
poolExecutor.submit(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
poolExecutor.shutdown();
}
}
06-自定义线程池参数详解
任务队列:按照上面的传参,核心线程数为2,最大线程数为5。那现在我有10个任务怎么办?多出的5个任务,放到任务队列中,等有空闲线程了,再从队列获取任务并执行。
创建线程工厂:按默认的方式创建线程对象。
拒绝策略:
什么时候拒绝任务
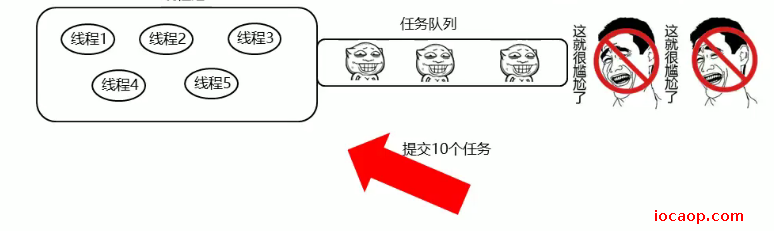
当提交的任务大于(线程池最大线程数+任务队列容量)时,就会拒绝。
如何拒绝
四种拒绝策略:
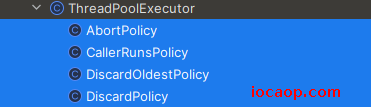
AbortPolicy:也是默认策略,丢弃任务,抛出异常RejectedExecutionExceptionDiscardPolicy:不推荐,丢弃任务,不抛异常。DiscardOldestPolicy:丢弃等待队列中等待最久的任务,并把当前任务加入队列。CallerRunsPolicy:调用run()方法,绕过线程池,直接执行。
试一下触发拒绝策略:
/**
* 触发拒绝策略
*
* @author 赖卓成
* @date 2023/06/27
*/
public class MyThreadPoolDemo04 {
public static void main(String[] args) {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(2, 5, 10, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
Executors.defaultThreadFactory(), new AbortPolicy());
for (int i = 0; i < 16; i++) {
poolExecutor.submit(()->{
System.out.println(Thread.currentThread().getName()+"执行了");
});
}
}
}
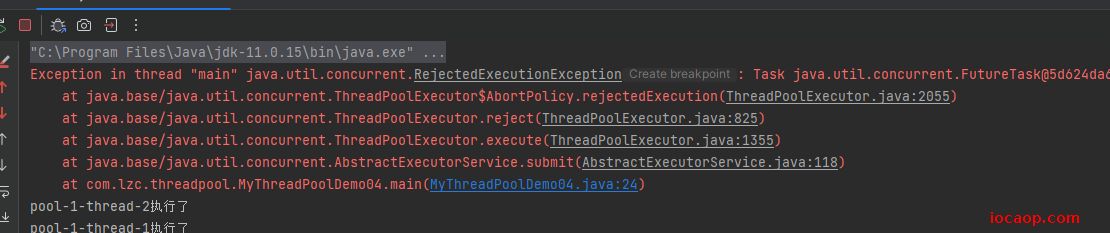
最大线程数+阻塞队列容量为15,我们提交16个任务,导致抛出异常。
07-非默认任务拒绝策略
试试其他几种拒绝策略:
微调一下:
/**
* 触发拒绝策略
*
* @author 赖卓成
* @date 2023/06/27
*/
public class MyThreadPoolDemo04 {
public static void main(String[] args) {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(1, 2, 10, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(), new AbortPolicy());
for (int i = 0; i < 6; i++) {
int finalI = i;
poolExecutor.submit(()->{
System.out.println(Thread.currentThread().getName()+"执行了---"+ finalI);
});
}
poolExecutor.shutdown();
}
}
分别测试不同的策略:
DiscardPolicy:丢弃任务,不抛异常。
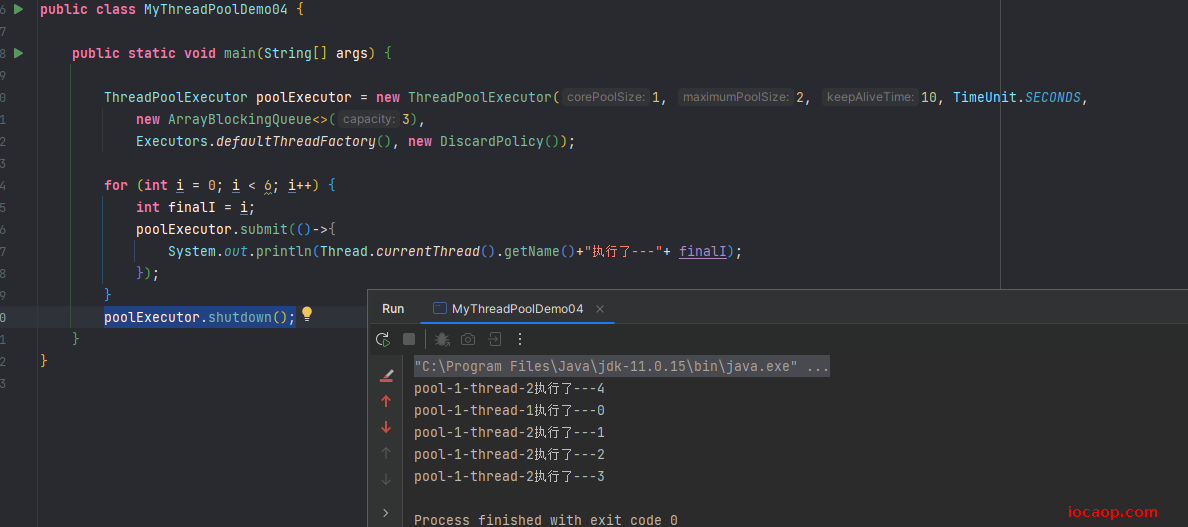
看出来,丢弃了一个任务,没有打印5
DiscardOldestPolicy:丢弃等待时间最久的任务,将当前任务添加到队列。
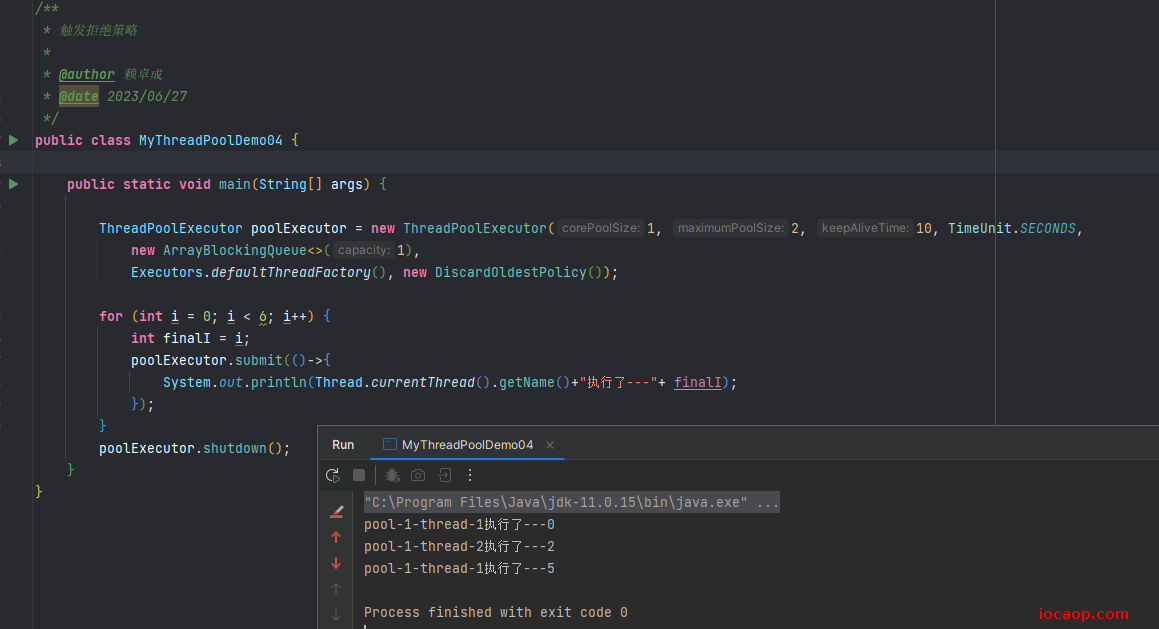
这里需要画图理解:

需要搞清楚的是:
什么时候创建核心线程:
当你创建一个线程池时,初始时会创建一定数量的核心线程。这些核心线程会一直存在,即使它们当前没有执行任务,以保持线程池的最小线程数。
什么时候创建非核心线程:
在需要执行任务时,线程池首先尝试将任务分配给核心线程来执行。只有当任务队列已满时,才会创建额外的线程(非核心线程)来执行任务。当任务队列中的任务得到处理后,非核心线程会被销毁,以保持线程池的大小在核心线程数范围内。
什么时候将任务放到队列:
核心线程数都被占用了,放到任务队列。
什么时候触发拒绝策略:
线程池满了,任务队列满了的时候。
什么时候丢弃任务:
触发拒绝策略时根据策略丢弃。
细节:
根据这个拒绝策略,达到最大线程池,再次执行该任务的提交流程: 核心线程->队列->非核心线程, (但是这里的核心线程不管是不是执行完任务1,都会放到队列中,因为在任务1的时候,核心线程已经作为该核心线程的第一个任务firstTask, 也就是核心线程(这里只有一个核心)在首个任务之后,之后的任务都会先放到队列, 然后由线程(两个线程谁拿到了谁就去执行,但是根据执行结果来看,说明两个线程的第一个任务都没执行结束)去队列拿任务。
放队列的前提是核心线程已经有了(而不是核心线程是否在执行任务),就算此时核心线程的任务1执行结束,还是会先放到队列,然后线程再去队列中拿任务
08-volatile-问题
代码:
public class Money {
/**
* 钱 初始值为10w
*/
public static int money = 100000;
}
public class MyThread01 extends Thread{
@Override
public void run() {
while(Money.money==100000){
}
System.out.println("余额已不是10w");
}
}
public class MyThread02 extends Thread{
@Override
public void run() {
try {
Thread.sleep(1000L);
Money.money = 0;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
public class VolatileDemo01 {
public static void main(String[] args) {
MyThread01 myThread01 = new MyThread01();
myThread01.start();
MyThread02 myThread02 = new MyThread02();
myThread02.start();
}
}
运行结果,没有任何输出,程序也不停止。正常来说,应该会打印:余额已不是10w。并且跳出循环,结束程序。
这里却没有打印,为什么?
09-volatile-问题解决
这个问题,要从JMM模型角度分析。画图:
当两个线程刚启动时,线程的栈内存,会读取主寸变量,复制一份到栈内存作为副本:
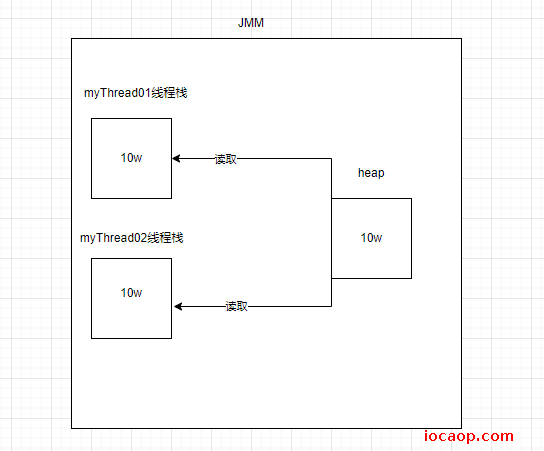
当线程2修改了本地变量后,需要写回到主存:
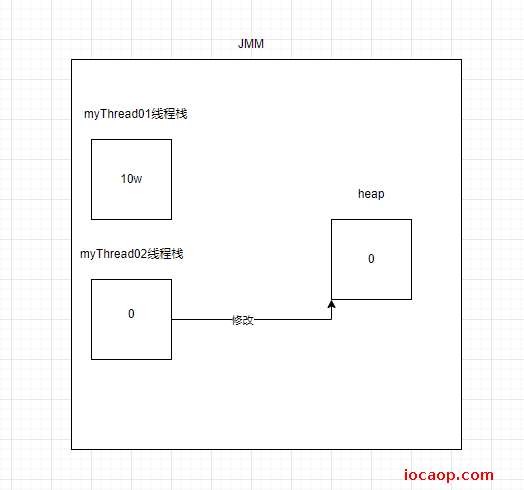
这时候,如果线程1没有重新读取刷新本地变量副本,就还是10w,出现了上一节课的情况。
- 堆内存是唯一的,每个线程都有自己的线程栈
- 每一个线程在使用栈里面的变量的时候,都会先拷贝一份到变量副本中。
- 在线程中,每一次使用是优先从变量的副本中获取的。
如果A线程修改了堆中共享变量的值,那么其他线程不一定能及时使用最新的值。
解决:
使用volatile关键字修饰,强制线程每次在使用被修饰变量时,都会看一下共享区域的最新值。
使用:
public class Money {
/**
* 钱 初始值为10w
*/
public static volatile int money = 100000;
}
加上以后,运行:
这个模型和cpu、内存、cache很相似,可以看看:点击跳转
10-synchronized解决
这个课讲的不够深入,没有讲synchronized的原理,放在后续计划。
同步代码会有以下步骤:
- 线程获得锁
- 清空线程中变量副本
- 拷贝主存中共享变量的最新值到变量副本
- 执行代码
- 修改变量副本后同步给主寸的共享数据
- 释放锁
代码:
public class Money {
/**
* 钱 初始值为10w
*/
public static int money = 100000;
/**
* 锁对象
*/
public static Object lock = new Object();
}
public class MyThread01 extends Thread {
@Override
public void run() {
// 循环获取锁,直到变量被修改,才跳出循环
while (true) {
synchronized (Money.lock) {
if (Money.money != 100000) {
System.out.println("余额已不是10w");
break;
}
}
}
}
}
public class MyThread02 extends Thread{
@Override
public void run() {
// 只需要拿一次锁,修改变量即可
synchronized (Money.lock) {
try {
Thread.sleep(1000L);
Money.money = 0;
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class VolatileDemo01 {
public static void main(String[] args) {
MyThread01 myThread01 = new MyThread01();
myThread01.start();
MyThread02 myThread02 = new MyThread02();
myThread02.start();
}
}
运行结果:实现原理是volatile+cas,所以也可以保证可见性。
11-5-原子性和并发操作工具
11-原子性
一次操作或者多次操作中,要么所有操作都得到了执行且不会收到任何因素干扰而中断,要么都不执行,多个操作是一个不可分割的整体。
先写个demo:
public class MyRunnable implements Runnable{
private static int count = 0;
@Override
public void run() {
for (int i = 0; i < 100; i++) {
count++;
System.out.println("count = " + count);
}
}
}
public class MyAtomDemo01 {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
for (int i = 0; i < 100; i++) {
new Thread(myRunnable).start();
}
}
}
开启100个线程,每个线程对count自增100次,结果应该是1w,但是运行的结果是:
学习了JMM模型后可以知道:
- 线程需要从主存读取变量副本到线程栈
- 线程操作线程栈中的副本,自增
- 线程需要将最新的变量副本写回主存
在上面三部,不是原子的,在线程将最新的变量副本写回到主存之前,cpu的执行权被其他线程抢走。比如。count为100,线程1执行自增,变量副本为101,但是还没写回主存,这时候,线程2抢走cpu执行权,线程2从主存拿到的count还是100。这时候,即使线程1再将变量副本写回主存,也保证不了count是正确的。两个线程写回主存时,都是101,正确的应该是102。
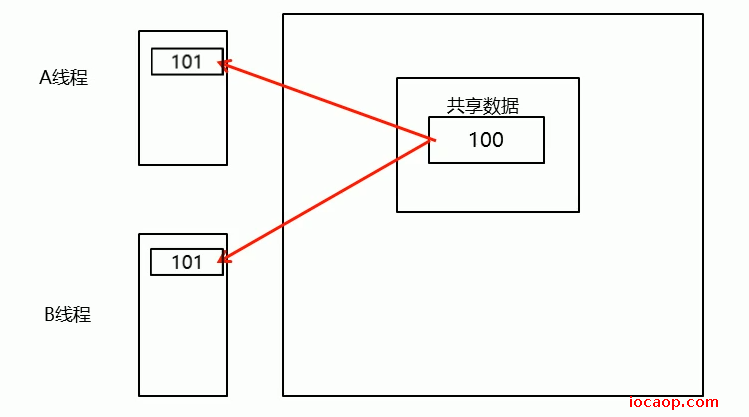
count++不是一个原子性操作,在执行的过程中,有可能被其他线程打断。其他线程打断后,其他线程操作了共享数据,这个线程忽略了其他线程的修改,用的还是旧值。如主存是1,线程A读进来是1,线程B读进来也是1,线程A写回主存前,线程B修改为了2,线程A忽略线程B的修改,直接做自己的操作,然后写回主存。
12-volatile不能保证原子性
volatile关键字能不能解决上节课遇到的问题?
试一下就知道了:
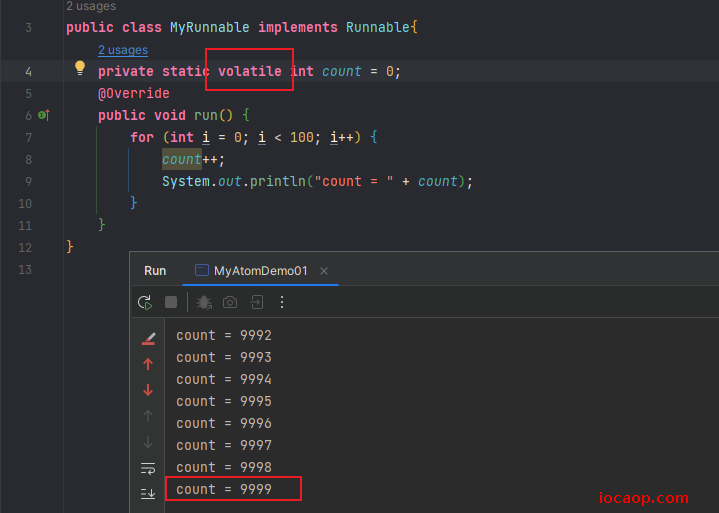
并不能:volatile保证的是可见性,保证线程每次都获取主存中共享数据的最新值,但是我们这个问题是,线程1还没有将自增以后的变量副本写回到主存,线程2就读取了共享数据。问题在主存中的共享数据还没有被写入,而不是线程2没有获取最新的共享数据。
synchronized锁能解决这个问题吗?可以
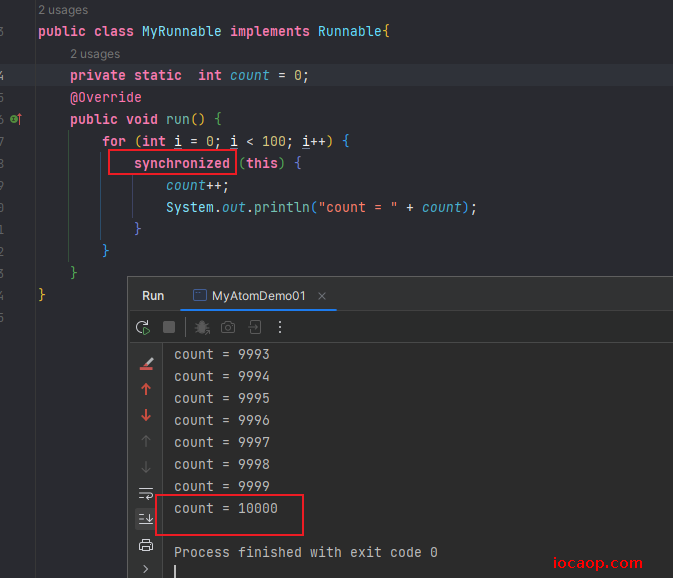
可以解决,因为synchronized加了锁,当线程1没有执行完,其他线程来,获取不到锁,不会往下执行,会等待。
13-AutomaticInteger-基本使用
上面已经使用synchronized解决了问题,但是速度比较慢。因为每次线程在操作共享数据时,都需要先获得锁,再判断是否获得锁,执行完,还要释放锁。
jdk5以后,提供了atomic包,用来解决多线程计算共享数据的问题。
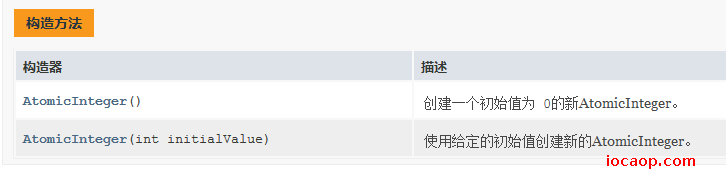
public AtomicInteger(): 初始化一个默认值为0的原子型Integer
public AtomicInteger(int initialValue): 初始化一个指定值的原子型Integer
int get(): 获取值
int getAndIncrement(): 以原子方式将当前值加1,注意,这里返回的是自增前的值。
int incrementAndGet(): 以原子方式将当前值加1,注意,这里返回的是自增后的值。
int addAndGet(int data): 以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果。
int getAndSet(int value): 以原子方式设置为newValue的值,并返回旧值。
这节比较简单,不写代码了。
14-AtomicInteger-内存解析
再说一次,为什么已经使用了synchronized解决了上面的问题,还需要用这个玩意?因为synchronized需要走三步:
判断并获取锁
操作共享数据
释放锁
效率低,所以用AtomicInteger是更好的选择。
改写代码:
public class MyRunnable implements Runnable {
private static final AtomicInteger count = new AtomicInteger();
@Override
public void run() {
for (int i = 0; i < 100; i++) {
synchronized (this) {
int andGet = count.incrementAndGet();
System.out.println("count = " + andGet);
}
}
}
}
public class MyAtomDemo04 {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
for (int i = 0; i < 100; i++) {
new Thread(myRunnable).start();
}
}
}
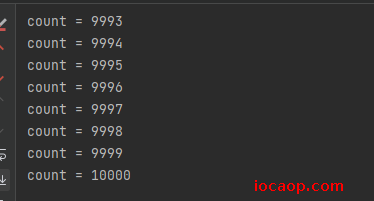
我们已经分析了问题是:线程读取主存到栈内存变量副本->操作变量副本->将变量副本写回到主存
这三步不是原子操作,使用
AtomicInteger就可以保证这三步的原子性,要么全部执行,要么全部不执行。
原理:
自旋锁+CAS
CAS算法:
有三个操作数(内存值V,旧的预期值A,要修改的值B):
- 当旧的内存值A==内存值V时,将内存值V改为B。
- 当旧的内存值A!=内存值V时,不做任何操作,并重新获取现在的值。(这个重新获取的动作就是自旋)
假设现在线程A和线程B都要修改内存中的100,线程A读取了主存的值100作为旧值,线程B也读取了主存的值100作为旧值。线程A先修改,旧值为100,内存值为100,相等,允许修改,内存值本改为101。修改完后,线程B也来修改,线程2的旧值是100,内存值是101,不相等,如下图:
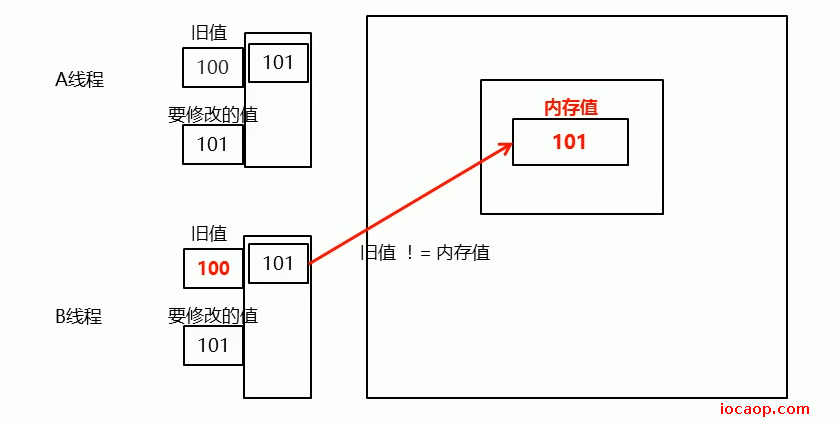
这时候,需要自旋,重新将内存的值读到线程B:
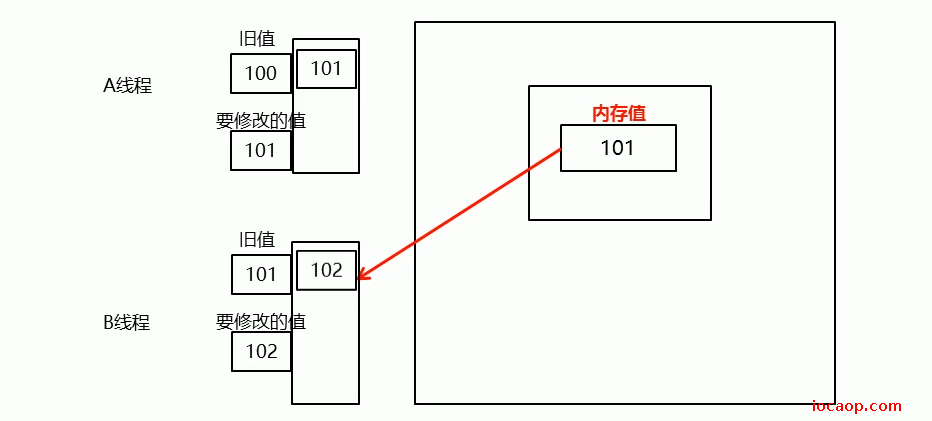
重新读取后,再按CAS判断一遍,确保共享数据没有被其他数据修改过,才允许操作。
CAS算法:修改共享数据的时候,把原来的值记录了下来,线程操作完变量副本后,需要比较,如果内存中的值和记录的旧值一样,证明其他线程没有操作过,才运行将变量副本中的值写回主存,如果主存中的值和读取到线程中的记录的旧值不一样,则是其他线程操作过,需要自旋,重新将主存中的值读到线程中。
15-AtomicInteger-源码解析
这里我们学习一下incrementAndGet就好了。
首先AtomicInteger类中有个变量,使用volatile进行修饰,保存的是旧值
// 获取Unsafe对象,用于操作内存
private static final jdk.internal.misc.Unsafe U = jdk.internal.misc.Unsafe.getUnsafe();
// 获取int类型变量value的偏移量
private static final long VALUE = U.objectFieldOffset(AtomicInteger.class, "value");
// 当前AtomicInteger中的值
private volatile int value;
incrementAndGet方法,调用了Unsafe类中的方法getAndAddInt,我是Java11,Java8可能没有U这个变量,而是直接用,不记得了。
public final int incrementAndGet() {
// 参数1:AtomicInteger对象
// 参数2:value变量的便宜
// 参数3:需要增加的值 1
// 返回值:getAndAddInt返回的是自增前的值,所以这里+1
return U.getAndAddInt(this, VALUE, 1) + 1;
}
getAndAddInt,这个方法在Unsafe类:
@HotSpotIntrinsicCandidate
public final int getAndAddInt(Object o, long offset, int delta) {
// v用来存放主存中最新值
int v;
do {
// 通过AutomaticInteger对象和value的偏移,获取最新的值
v = getIntVolatile(o, offset);
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
// 获取到最新值后调用weakCompareAndSetInt
// 参数1:AutomaticInteger对象
// 参数2:value的偏移
// 参数3:最新值
// 参数3:修改为多少
// 返回值:最新值和AutomaticInteger对象中的值比较,如果相等返回true,如果不相等则返回false,一直自旋
// 返回最新的值(修改前的最新值)
return v;
}
weakCompareAndSetInt方法:
@HotSpotIntrinsicCandidate
public final boolean weakCompareAndSetInt(Object o, long offset,
int expected,
int x) {
return compareAndSetInt(o, offset, expected, x);
}
compareAndSetInt方法:本地方法,比较交换 o+offset获取当前的值,传入的expected旧值比较,x为修改为多少。
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt(Object o, long offset,
int expected,
int x);
16-悲观锁和乐观锁
synchronized和CAS的区别
相同点:再多线程情况下,都可以保证共享数据的安全性。
不同点:
synchronized总是从最坏的角度触发,认为每次获取数据的时候,别人都可能修改。所以每次操作共享数据之前,都会上锁,操作完后释放锁。(悲观锁)- CAS是从乐观的角度出发,假设每次操作数据别人都不会修改,不上锁,只不过在操作共享数据的之前,检查一下别人有没有修改过。修改过则重新获取最新的值,没有修改过则直接操作。(乐观锁)。
17-并发工具类-Hashtable
先看一个HashMap线程安全问题Demo:
/**
* HashMap线程安全问题演示
*
* @author lzc
* @date 2023/06/29
*/
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, Integer> map = new HashMap<>();
new Thread(()->{
for (int i = 0; i < 25; i++) {
map.put(""+i,i);
}
}).start();
new Thread(()->{
for (int i = 25; i < 51; i++) {
map.put(""+i,i);
}
}).start();
try {
// 此处睡眠,让主线程等待其他两个线程操作完map,再遍历
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
for (int i = 0; i <51; i++) {
System.out.println("map.get(i+\"\") = " + map.get(i + ""));
}
}
}
这个例子中,我使用了两个线程,分别往map添加元素,0-25,25-50。两个线程执行完以后,我再遍历,如果出现通过key获取value为null,则表示有线程安全问题。
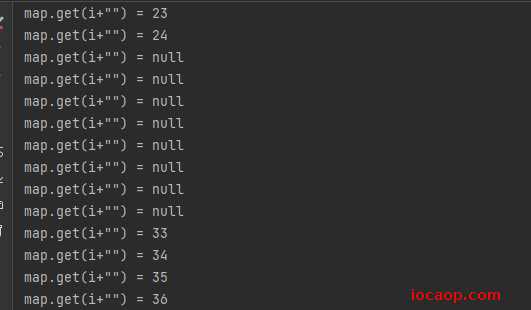
然后我将HashMap换为Hashtable,无论运行多少次,都不会出现线程安全问题。为什么?
复习下Hashtable,和HashMap相似,也是数组+链表

但是Hashtable加了悲观锁,只要有线程访问,就会将整张表全部锁住,操作完才会释放锁。其他线程访问,需要获得锁,才能操作。
通过翻看源码也能看出来:加了synchronized锁,是悲观锁。
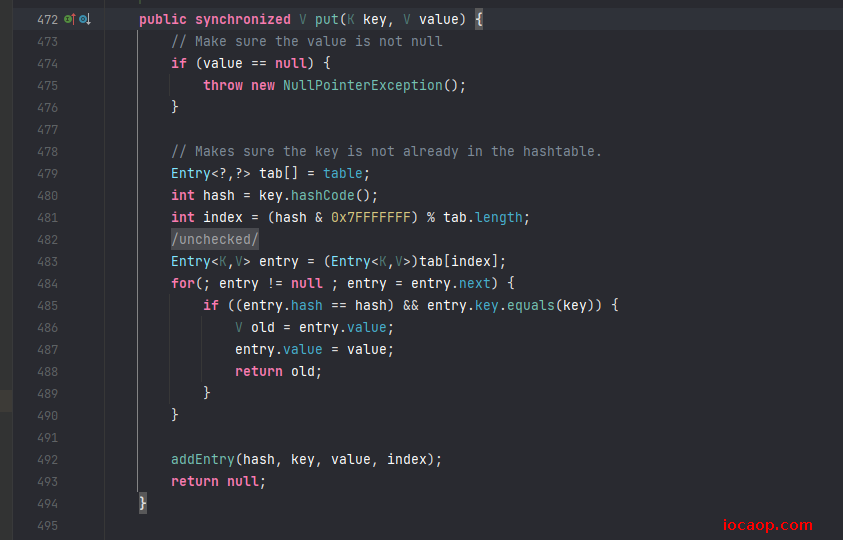
Hashtable采用悲观锁synchronized的方式保证数据安全,只要有线程访问,就会将整张表全部锁起来,所以效率低下。
18-并发工具类-ConcurrentHashMap基本使用
jdk1.5以后提供的,既能保证线程安全,也兼顾效率。
上一节课中,替换一行代码即可,其他不用动,因为ConcurrentHashMap实现了Map接口,当做Map来使用就行了。
Map<String, Integer> map = new ConcurrentHashMap<>();
HashMap线程不安全,多线程会有数据安全问题
Hashtable线程安全,但会锁住整张表,悲观锁,性能低
ConcurrentHashMap线程安全,效率相对高。jdk7和jdk8底层原理不一样。
19-ConcurrentHashMap-JDK1.7版本原理
创建一个默认的ConcurrentHashMap后,会在内存中创建一个长度为16、加载因子为0.75的数组(和HashMap一样)。这个数组的名字为Segment,然后会创建一个长度为2,名称为HashEntry的小数组,赋值给Segment数组的0索引,其他索引此时都是null。
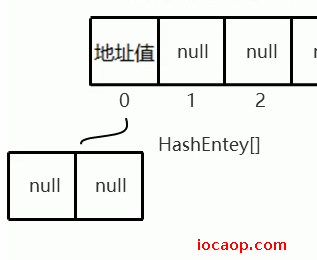
添加元素时,和HashMap一样,会先根据key的哈希值,计算出元素在Segment数组中的索引,假设是4,然后会判断该索引位置的元素是否为null,如果是null,并不会直接存,而是创建一个和0索引一样的Segment数组(长度默认为2):
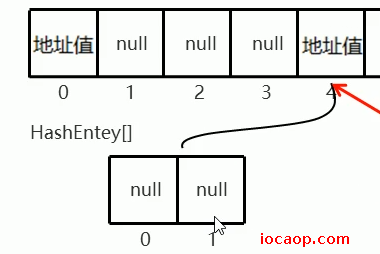
然后会根据键的哈希值,再次计算出元素在小数组Segment中的索引(二次哈希),假设是0且为null,则直接将元素添加进去:
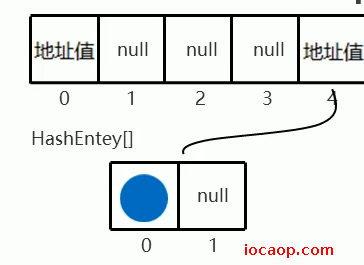
如果二次哈希计算出的索引位置是0,且元素不是null,则调用equals比较是否相同,如果相同不存,不同则会将新元素存入,旧元素挂在下面,形成哈希桶结构:
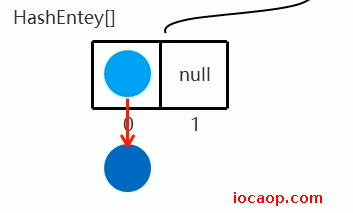
如果二次哈希计算出的索引位置是1,则需要扩容(加载因子也是0.75,扩容2倍):
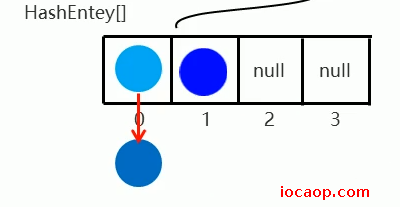
在这整个过程中,大数组Segment数组的长度永远是16,不会扩容,扩容的是小数组。
当整个Segment都满了以后,就相当于16个哈希表,凑在一起,凑成了一个大的哈希表。
如何保证线程安全的?
当线程进来,不会锁住整个大的Segment哈希表,只会锁住小的:
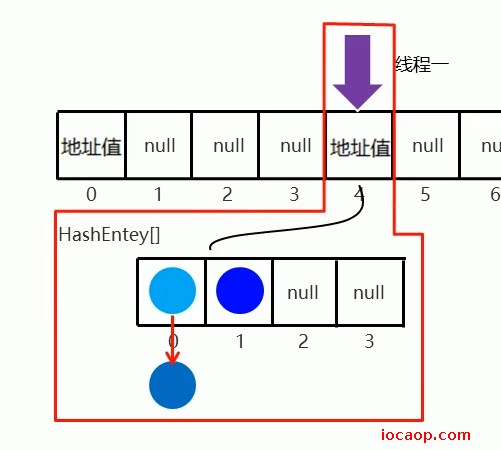
有其他线程需要操作该索引的小表,则需要等待锁。如果不是,则不需要等待锁。
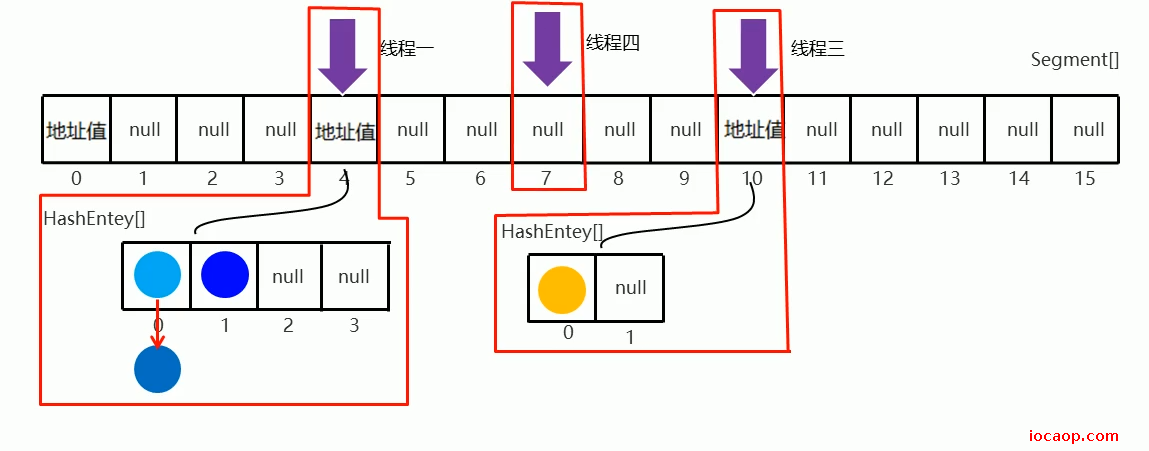
根据图可以知道,在1.7版本的ConcurrentHashMap中,默认情况下最大允许16个线程同时访问。
总结:
创建对象注意事项:
- 默认创建长度16,加载因子0.75的大数组,大数组一旦创建无法扩容,加载因子是给小数组用的。
- 还会创建一个长度为2的小数组,把地址给赋值给大数组0索引处,其他索引位置元素都是null。
添加元素时:
- 先根据键的哈希值计算出在大数组中的位置。如果大数组索引位置为null,则按照模板创建小数组,再做二次哈希,计算出小数组中应该存入的位置,直接存入。
- 如果大数组索引位置元素不为null,会根据所记录的地址值,找到小数组,二次哈希计算小数组中应该存入的位置,判断是否需要扩容,如果需要则扩容2倍,不需要,则判断该位置是否有元素,如果没有直接存,如果有则比较元素是否相同,相同则形成哈希桶,不同则直接存。
20-ConcurrentHashMap-JDK1.8版本原理
底层结构:哈希表(数组、链表、红黑树)
结合CAS机制+synchronized同步代码块保证线程安全。
空参构造:
/**
* Creates a new, empty map with the default initial table size (16).
*/
public ConcurrentHashMap() {
}
啥也没做?别忘了,构造函数会被默认假设super(),查看继承关系:
ctrl+alt+shift+u可以查看继承关系。
除此之外还有个方法:
ctrl+h也可以查看继承关系
翻看源码得知,并不是在构造函数创建的哈希表,是在put方法:
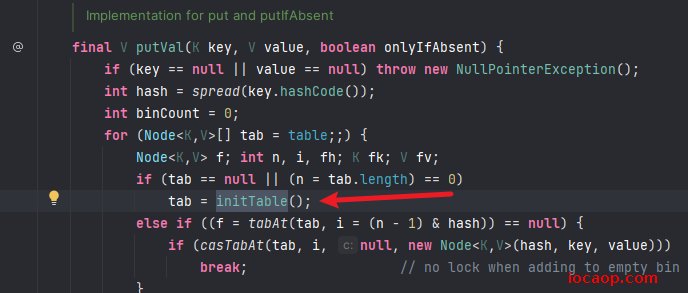
创建数组后:

存入元素时,会根据key做哈希,计算出元素位置,假设是4,第一次为null,会采取cas,进行数据添加:
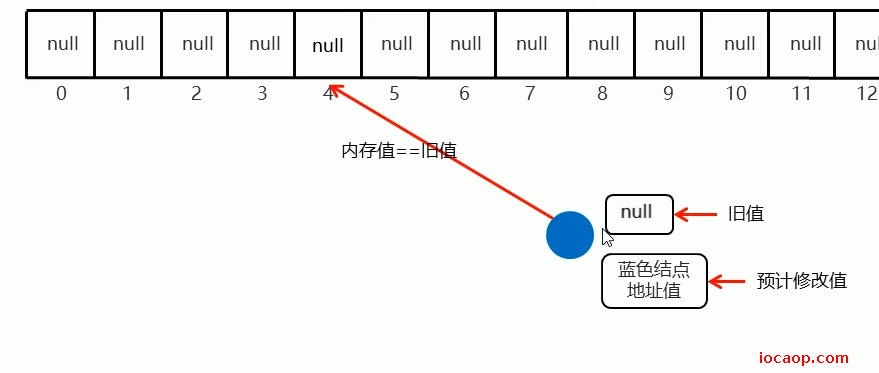
内存值等于旧值,则可以修改:
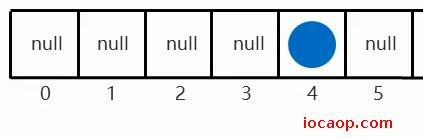
再次存入,计算出元素的索引也是4,则会利用volatile获得数组中最新节点的地址,挂在节点下面:
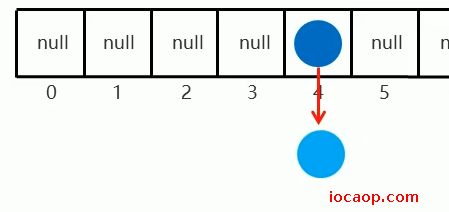
当挂得越来越多,就形成链表,链表长度大于8,则变成红黑树:
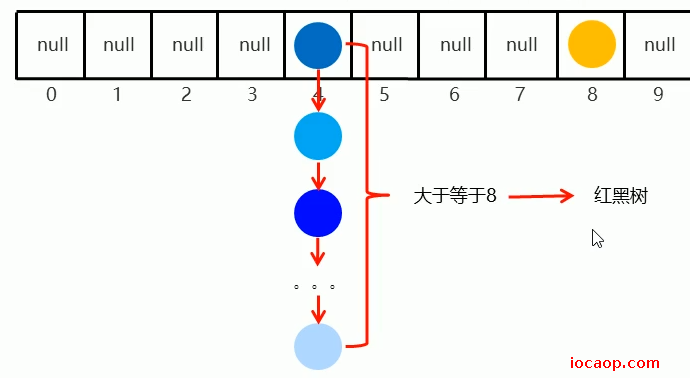
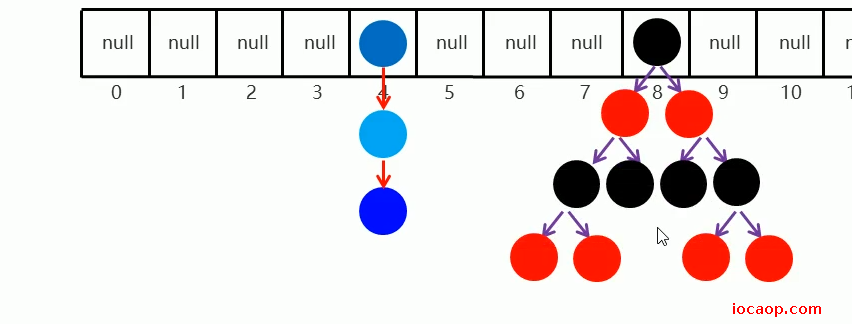
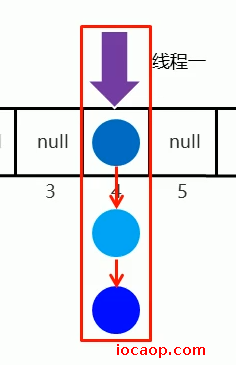
如何保证线程安全?
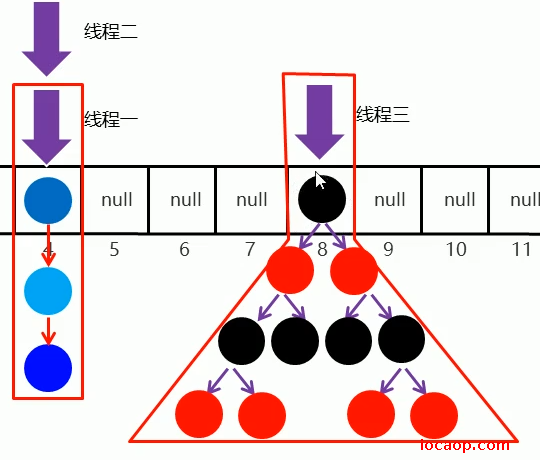
利用synchronized同步代码块,将链表或红黑树锁起来:锁对象为链表或红黑树的头结点
21-CountDownLatch
使用场景:让一条线程等待其他线程执行完毕之后再执行。

创建四个线程,模拟妈妈等待3个孩子吃完饺子后,收拾碗筷。
/**
* 母亲线程
*
* @author lzc
* @date 2023/07/04
*/
public class MothreThread extends Thread{
private CountDownLatch countDownLatch;
public MothreThread(CountDownLatch countDownLatch) {
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
// 等待孩子吃完饺子收拾碗筷
try {
countDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 收拾碗筷
System.out.println("孩子们都吃玩了,收拾碗筷");
}
}
创建了3个子线程,代码类似,for循环数量不一样。
/**
* 子线程
*
* @author lzc
* @date 2023/07/04
*/
public class ChildThread1 extends Thread{
private CountDownLatch countDownLatch;
public ChildThread1(CountDownLatch countDownLatch) {
this.countDownLatch = countDownLatch;
}
@Override
public void run() {
// 吃饺子
for (int i = 0; i < 10; i++) {
System.out.println(super.getName()+"吃完了第"+i+"个饺子");
}
// 吃完了告诉他妈
countDownLatch.countDown();
}
}
/**
* @author lzc
* @date 2023/07/04
*/
public class MyCountDownLatchDemo {
public static void main(String[] args) {
// 创建CountDownLatch对象 传递给其他线程 参数为等待线程的数量
CountDownLatch countDownLatch = new CountDownLatch(3);
// 创建四个线程
MothreThread mothreThread = new MothreThread(countDownLatch);
mothreThread.setName("母亲线程");
mothreThread.start();
ChildThread1 childThread1 = new ChildThread1(countDownLatch);
childThread1.setName("孩子1");
childThread1.start();
ChildThread2 childThread2 = new ChildThread2(countDownLatch);
childThread2.setName("孩子2");
childThread2.start();
ChildThread3 childThread3 = new ChildThread3(countDownLatch);
childThread3.setName("孩子3");
childThread3.start();
}
}
运行结果:

创建对象就是在底层创建了一个计数器,计数器的值就是我们传的参数,每次其他线程调用
countDownLatch.countDown();计数器就会减1,当计数器减到1的时候,就会自动唤醒countDownLatch.await();等待的线程。
22-Semaphore
使用场景:控制访问特定资源的线程数量
编码模拟公路,只能同时通过两辆汽车。
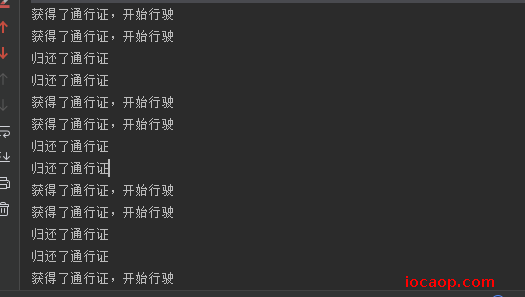
public class MyRunnable implements Runnable{
private Semaphore mr = new Semaphore(2);
@Override
public void run() {
// 获得通信证
try {
mr.acquire();
// 行驶
System.out.println("获得了通行证,开始行驶");
Thread.sleep(100L);
// 行驶完毕,归还通行证
System.out.println("归还了通行证");
mr.release();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
public class MySemaphoreDemo {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
for (int i = 0; i < 100; i++) {
Thread thread = new Thread(myRunnable);
thread.start();
}
}
}
运行结果:可以控制每次只能两辆车同时通过,当通过归还通行证,其他汽车获取通行证后,才可以通过下一辆。控制了特定资源的线程访问数量。