MySQL基础复习
B站视频:点击跳转
p2-为什么要使用数据库及数据库常用概念
- 持久化,把数据保存到可掉电式存储设备中供之后使用。数据持久化意味着将内存中的数据保存到硬盘加以固化。
- 持久化的主要作用是将内存中的数据存储在关系型数据库中,也可以存在磁盘文件,xml数据中。
为什么非要数据库不存文件?查找方便,读取快,易打开,数据类型复杂存文件不好区分。
2-1 数据库相关概念
DB:数据库
存储数据的仓库,本质是一个文件系统,保存了一系列有组织的数据。
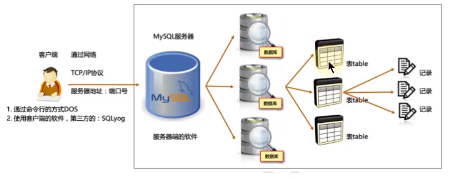
DBMS:数据库管理系统
是操纵和管理数据的大型软件,用于建立、使用和维护数据库,对数据进行同一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。
SQL结构化查询语言(structured query language)
专门用来与数据库通信的语言
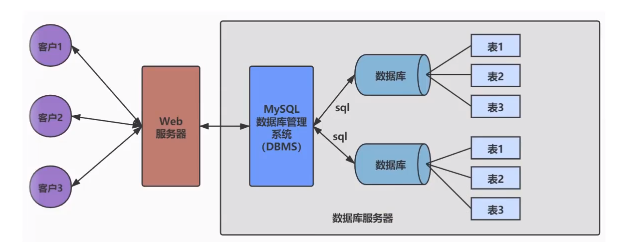
2-2 数据库与数据库管理系统的关系
数据库管理系统可以管理多个数据库,关系如图:
2-3 为什么选择MySQL?
- 开源,使用成本低。
- 性能卓越、使用成本低。
- 软件体积小,使用简单,易于维护。
- 历史悠久、社区活跃度高,遇到问题可以寻求帮助。
- 许多互联网公司用,经历了时间的验证。
2-4 Oracle和MySQL
Oracle适合大型跨国企业使用,因为他们对费用不敏感,但是对性能要求和安全性有更高的要求。
MySQL体积小、速度快、总体拥有成本低,可处理成千上万条记录的大型数据库,开源,使得很多互联网公司、中小型网站选择MySQL作为网站数据库。如阿里、去哪儿、美团外卖、腾讯。
p4-关系型数据库和非关系型数据库
参考redis课程笔记:点击跳转
p5-ER模型与表记录的4种关系
5-1 表、记录、字段
ER(实体-联系)三个概念 :实体集、属性、联系集
一个实体集对应数据库中的一个表,一个实体对应于数据库表中的一条记录(row),一个属性对应一个字段(column)。
orm思想(Object Relational Mapping)
表->类
记录->对象
字段->成员变量
5-2 表的关联关系
- 一对一
- 一对多
- 多对多
- 自引用
p12-SQL概述和分类
12-1 SQL概述
sql是一种规范,是访问数据库的标准计算机语言,mysql特有的语法是方言。sql标准在迭代,如sql89,sql92,sql99。
12-2 SQL分类
- DDL数据定义语句(create、alter、drop、rename、truncate)
- DML数据操作语言(insert、delete、update、select)
- DCL数据控制语言(commit、rollback、savepoint、grant、revoke)
- DQL数据库查询语言(select)
- TCL事务控制语言(commit、rollback)
参考w3c:点击跳转
12-3 SQL基本规则
- SQL可以写在一行或多行,为了提高可读性,各字句分行写,必要时使用缩进
- 每条命令以;或\g或\G结束
- 关键字不能被缩进也不能分行
- 关于标点符号
- 必须保证所有的括号,单引号,双引号是成对的
- 使用英文半角输入方式
- 字符型和日期时间类型的数据可以使用单引号表示
- 列的别名尽量使用双引号,不建议省略as
12-4 SQL大小写规范
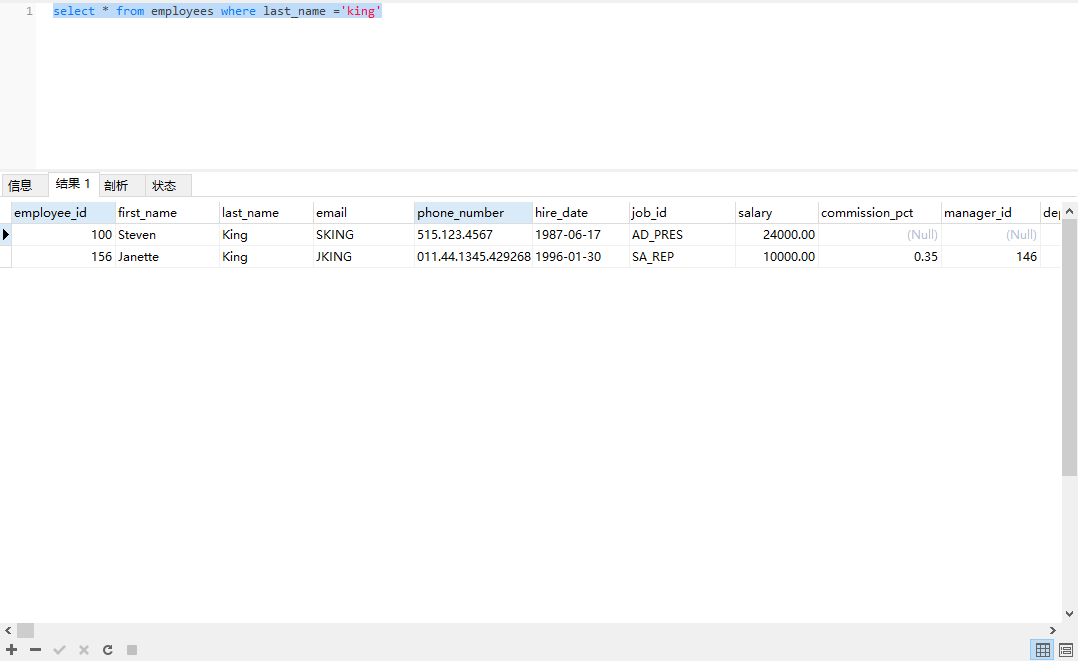
- MySQL在Windows环境下大小写不敏感
- MySQL在linux环境下大小写敏感
- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名、列的别名是忽略大小写的
- 推荐采用的书写规范
- 数据库名、表名、表别名、字段名、字段别名等用小写
- SQL关键字、函数名、绑定变量等用大写
p14-最基本的SELECT FROM
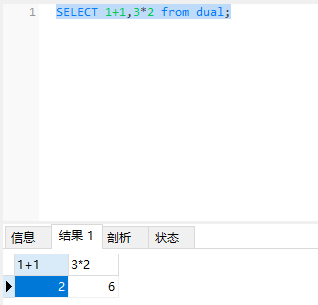
SELECT 1+1,3*2 from dual;
dual是伪表。
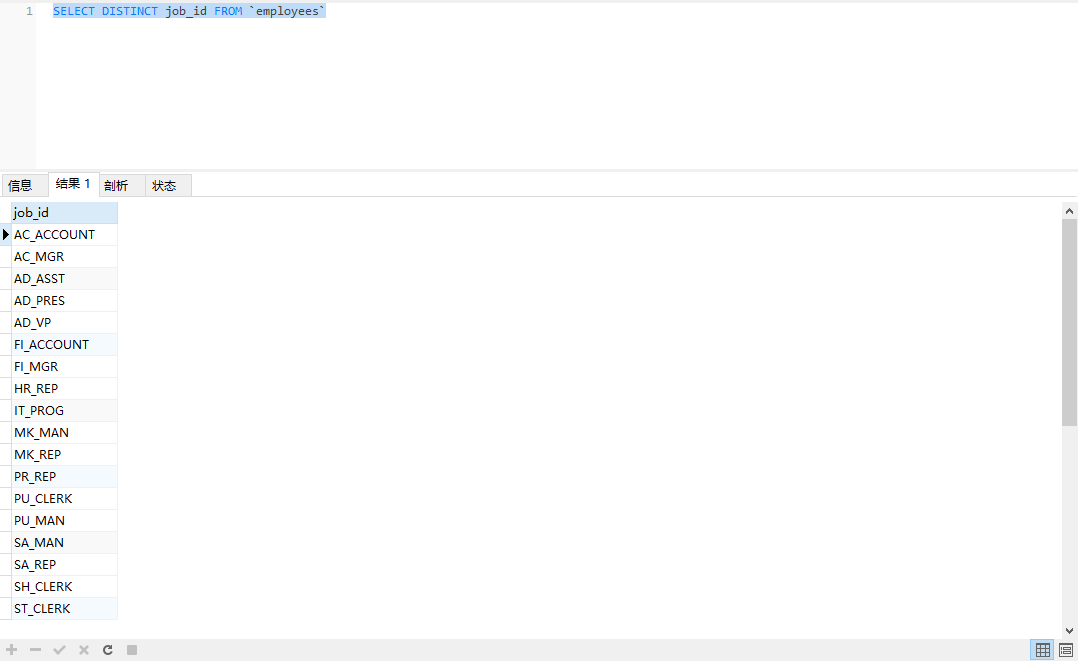
14-1 去重
在需要去重的字段前加上DISTINCT:
SELECT
DISTINCT job_id
FROM `employees`
14-2 空值参与运算
SELECT employee_id,
salary as '月工资',
commission_pct as '奖金率',
(1+commission_pct)*12*salary as '年工资'
FROM `employees`
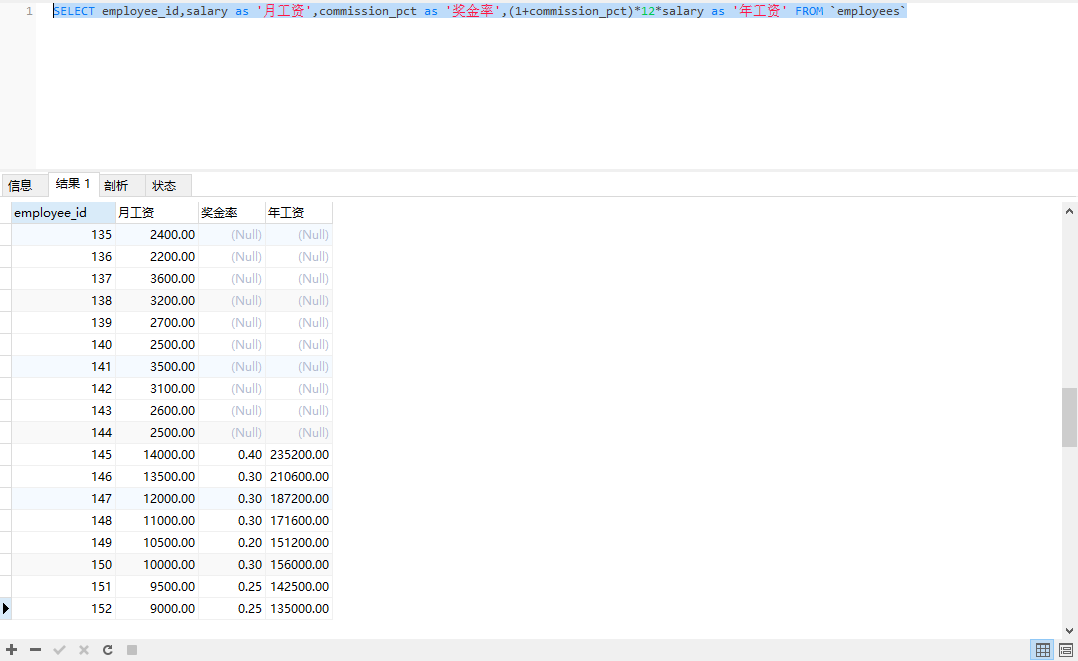
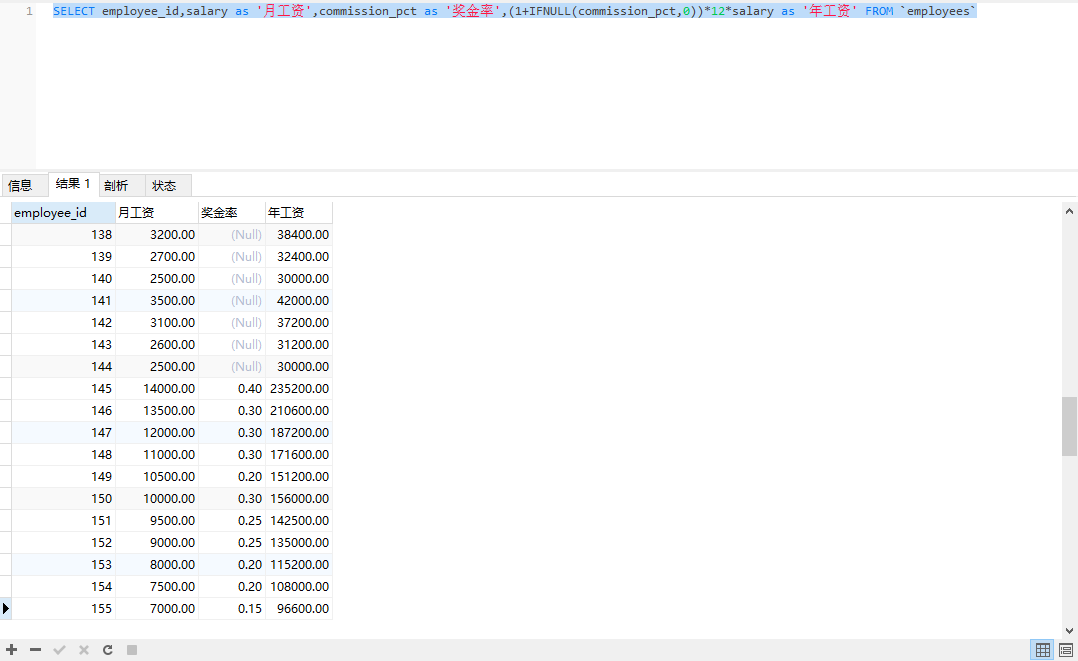
可以看到,有些员工没有奖金率,年工资被算成了null,显然不合理。所以引入IFNULL函数
SELECT
employee_id,
salary as '月工资',
commission_pct as '奖金率',
(1+IFNULL(commission_pct,0))*12*salary as '年工资'
FROM `employees`
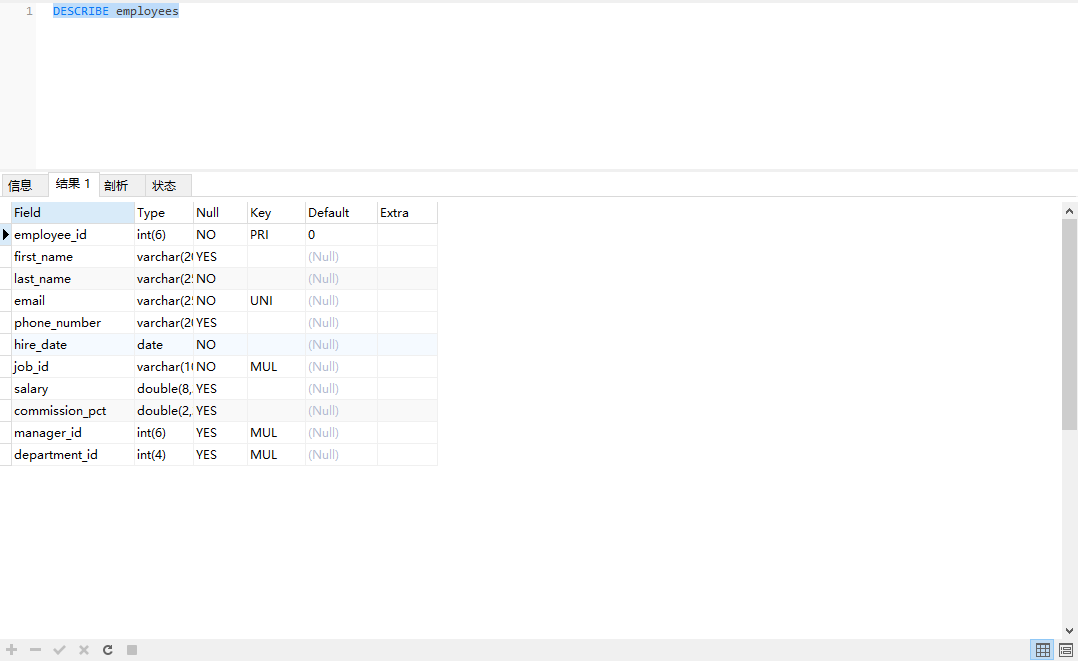
14-3 显示表结构
DESCRIBE employees
14-4 MySql大小写不敏感
p25-为什么需要多表查询?
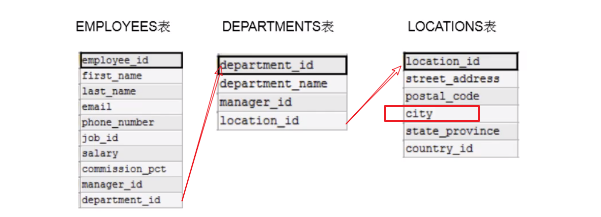
现在要查某个员工所在城市的名字,需要先根据员工姓名到employees表查询员工拿到员工的department_id,再到departments表根据department_id查询到的记录拿到location_id,到locations表,根据location_id查询记录,拿到city。如果不进行多表查询,就需要查询三次。
如果不进行多表查询,需要进行三次单表查询,如下:
select * from employees where last_name ='Abel';
select * from departments where departments_id = 80;
select * from locations where location_id = 2500;
我们知道,一般我们查询数据库是通过编程语言进行查询,web服务器和数据库就需要进行三次交互,期间的http请求就需要有三次,耗费时间变长,所以使用多表查询,就只需要一次请求。
既然需要查询三次,为什么不把上面的三张表合成一张表?
大部分查询不需要所有字段,会有很多冗余字段,对于不常用的字段,可以放在另外的表。减少orm加载字段的个数,除此之外还会有锁表的问题。
p26-笛卡尔积多表连接
26-1 笛卡尔积(交叉连接)的理解
数学运算,假设有两个集合X(a,b,c)、Y(x,y),他们中的元素的所有可能的组合,就是笛卡尔积。
26-2 多表查询(关联查询)
笛卡尔积后加上连接条件才是正确的多表查询方式,连接条件至少有n-1个,n是表的个数。
SELECT
employee_id,
department_name
FROM
employees,
departments
WHERE
employees.department_id = departments.department_id
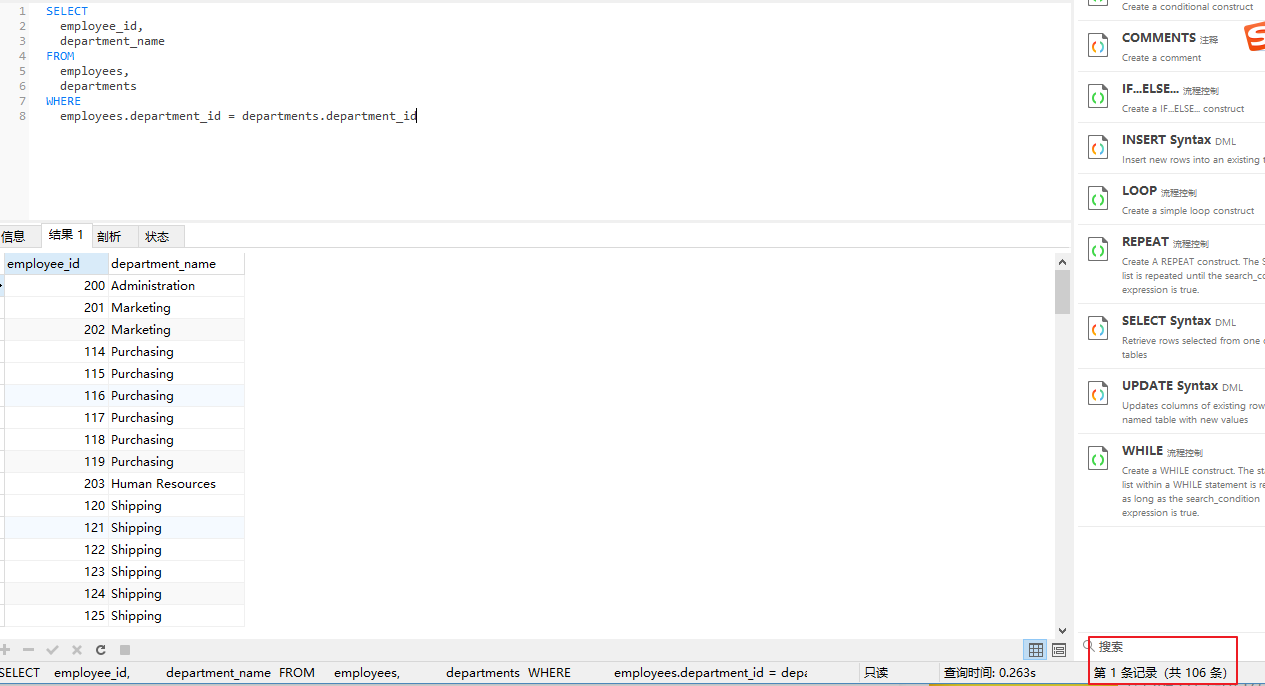
在SQL优化的角度,多表查询时,每个字段前都应该指明其所在的表,节省在查询过程中在表中寻找字段的时间。
如果给表起了别名,在之后的select或者where语句中,则必须使用别名,不能再使用表的原名。
p28-SQL92与SQL99内连接和外连接
28-1 左外连接
上面的多表查询,相当于内连接,如果需要查询所有员工的数据,则需要使用左外连接。
MySQL不支持SQL92外连接的写法:
在最后补上(+)表示左外连接
SELECT
employee_id,
department_name
FROM
employees,
departments
WHERE
employees.department_id(+) = departments.department_id
会报错。

oracle是支持的。
MySQL使用SQL99进行外连接。
SELECT
employee_id,
department_name
FROM
employees
LEFT JOIN departments ON employees.department_id = departments.department_id
28-2 满外连接
MySQL不支持FULL OUTER JOIN
需要配合UNION来实现。将两个查询的结果集合并,并且去重,去重效率会低一些。
UNION ALL合并查询结果集,不去重。
p29-7种join
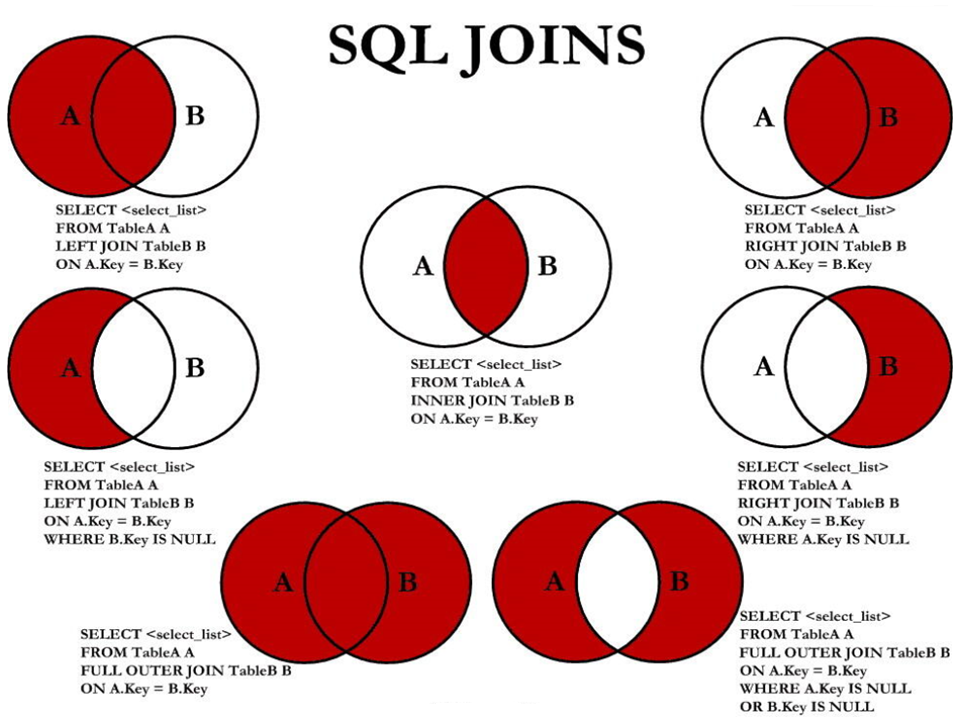
用下面两张表来写SQL
左上图为左外连接:
SELECT
employee_id,
department_name
FROM
employees
LEFT OUTER JOIN departments ON employees.department_id = departments.department_id
右上图为右外连接
SELECT
employee_id,
department_name
FROM
employees
RIGHT OUTER JOIN departments ON employees.department_id = departments.department_id
左中图为左外连接再去除右边表的数据可以使用IS NULL来实现:
SELECT
employee_id,
department_name
FROM
employees
LEFT OUTER JOIN departments ON employees.department_id = departments.department_id
WHERE
departments.department_id IS NULL
中图为内连接:
SELECT
employee_id,
department_name
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
右中图为右外连接再去除左表数据,也是使用IS NULL来过滤左表的数据:
SELECT
employee_id,
department_name
FROM
employees
RIGHT OUTER JOIN departments ON employees.department_id = departments.department_id
WHERE
employees.department_id IS NULL
左下图为满外连接可以用左上图UNION ALL右中图:
SELECT
employee_id,
department_name
FROM
employees
LEFT OUTER JOIN departments ON employees.department_id = departments.department_id UNION ALL
SELECT
employee_id,
department_name
FROM
employees
RIGHT OUTER JOIN departments ON employees.department_id = departments.department_id
WHERE
employees.department_id IS NULL
右下图则可以用左中图UNION ALL右中图:
SELECT
employee_id,
department_name
FROM
employees
LEFT OUTER JOIN departments ON employees.department_id = departments.department_id
WHERE
departments.department_id IS NULL UNION ALL
SELECT
employee_id,
department_name
FROM
employees
RIGHT OUTER JOIN departments ON employees.department_id = departments.department_id
WHERE
employees.department_id IS NULL
p30-SQL99语法新特性自然连接和using
30-1 自然连接
自然连接可以理解为等值连接,但是会自动查询表中所有相同的字段,进行等值连接。
用下面两张表来写SQL
SELECT
employees.employee_id,
departments.department_name
FROM
employees
NATURAL JOIN departments
和下面的sql查询结果是一样的:
SELECT
employees.employee_id,
departments.department_name
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
AND employees.manager_id = departments.manager_id
30-2 using
与自然连接不同的是,using指定了连接时表中具体的相同字段的名称。
以下sql的结果是一样的
SELECT
employees.employee_id,
departments.department_name
FROM
employees
INNER JOIN departments USING(department_id)
SELECT
employees.employee_id,
departments.department_name
FROM
employees
INNER JOIN departments ON employees.department_id = departments.department_id
p39-常用聚合函数
39-1 AVG、SUM、COUNT
求某列的平均数,相当于SUM/COUNT
SUM会统计不为NULL的行数的总和,COUNT会统计不为NULL的行数
在使用count时,尽量不适用count(字段名),因为有的记录该字段可能为NULL,导致求总数的结果不对。
p40-GROUP BY
用下面的表来写sql
40-1 分组简单使用
查询各个部门的员工的平均工资:
SELECT
department_id,
AVG( salary )
FROM
employees
GROUP BY
department_id
现在又要查询各个部门的各个工种的平均工资,在group by中加字段就好了:
SELECT
department_id,
job_id,
AVG( salary )
FROM
employees
GROUP BY
department_id,
job_id
select中出现的非组函数字段必须声明在group by 中。
40-2 WITH ROLLUP
在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。
SELECT
department_id,
AVG( salary )
FROM
employees
GROUP BY
department_id
WITH ROLLUP
需要注意使用ROLLUP时,不能同时使用ORDER BY进行结果排序,二者是互斥的。
p41-HAVING的使用与SQL语句执行过程
41-1 HAVING的使用
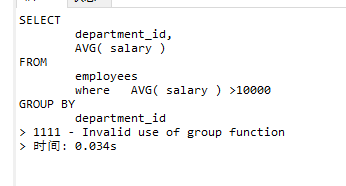
还是上表,需求:查出部门平均工资高于10000的部门
错误写法:
SELECT
department_id,
AVG( salary )
FROM
employees
where AVG( salary ) >10000
GROUP BY
department_id
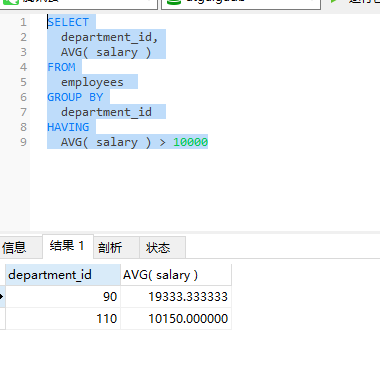
正确写法:
SELECT
department_id,
AVG( salary )
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) > 10000
如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE否则会报错。
HAVING必须写在GROUP BY的后面
HAVING一般配合GROUP BY使用,不然没有什么意义
41-2 SQL语句的执行过程
先看例子,还是之前的表,现在需要查询部门id为10、20、30、40这四个部门中,员工最高工资大于10000的信息。
方式1:
SELECT
department_id,
MAX( salary )
FROM
employees
WHERE
department_id IN ( 10, 20, 30, 40 )
GROUP BY
department_id
HAVING
MAX( salary )> 10000
方式2:
SELECT
department_id,
MAX( salary )
FROM
employees
GROUP BY
department_id
HAVING
MAX( salary )> 10000
AND department_id IN ( 10, 20, 30, 40 )
两条sql执行结果是一样的,但是执行效率方式1更高。
当过滤条件中有聚合函数时,此条件必须写在HAVING中,当过滤条件中没有聚合函数时,此条件可以写在WHERE中也可以写在HAVING中,但是建议写在WHERE中,效率更高
#sql92语法:
SELECT ....,....,....(存在聚合函数)
FROM ...,....,....
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
#sql99语法:
SELECT ....,....,....(存在聚合函数)
FROM ... (LEFT / RIGHT)JOIN ....ON 多表的连接条件
(LEFT / RIGHT)JOIN ... ON ....
WHERE 不包含聚合函数的过滤条件
GROUP BY ...,....
HAVING 包含聚合函数的过滤条件
ORDER BY ....,...(ASC / DESC )
LIMIT ...,....
SQL语句的执行过程:
- 先找到from后面的所有表,再进行笛卡尔积
- 根据连表ON的条件过滤掉不需要的数据
- 根据JOIN的方式过滤数据
- 根据WHERE条件过滤数据
- GROUP BY 分组
- HAVING 条件过滤数据
- SELECT过滤数据、DISTINCT去重
- ORDER BY 排序
- LIMIT分页
所以可以看出,方式1是先过滤(部门id为10、20、30、40)数据再分组,方式2是先分组再过滤(部门id为10、20、30、40)数据。方式1效率高。
p44-单行子查询案例分析
44-1 查询公司工资最少的员工的信息
SELECT
*
FROM
employees
WHERE
salary = (
SELECT
MIN( salary )
FROM
employees)
44-2 查询与141号员工的manager_id和department_id相同的其他员工的信息
方式1:
SELECT
*
FROM
employees
WHERE
manager_id = ( SELECT manager_id FROM employees WHERE employee_id = 141 )
AND department_id = ( SELECT department_id FROM employees WHERE employee_id = 141 )
AND employee_id <> 141
方式2:
SELECT * FROM employees WHERE ( manager_id, department_id )=( SELECT manager_id, department_id FROM employees WHERE employee_id = 141 )
AND employee_id <> 141
44-3 HAVING中的子查询:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT
department_id,
min( salary )
FROM
employees
GROUP BY
department_id
HAVING
min( salary )>(
SELECT
min( salary )
FROM
employees
WHERE
department_id = 50)
44-4 CASE中使用子查询
显示员工的employee_id,last_name和location。其中若员工department_id与location_id为1800的员工的department_id相同,则为Canada,其余为USA.
SELECT
employee_id,
last_name,
( CASE department_id WHEN ( SELECT department_id FROM departments WHERE location_id = 1800 ) THEN 'Canada' ELSE 'USA' END ) AS location
FROM
employees
p45多行子查询案例分析
45-1 多行子查询比较操作符
- IN,等于列表中的任意一个
- ANY,和单行比较操作符一起使用,和子查询返回的某一个值比较
- ALL,和单行比较操作符一起使用,和子查询返回的所有值比较
- SOME,同ANY
45-2 ANY和ALL的使用
需求:返回其他job_id中,比job_id为‘IT_PROG’部门任一工资低的,员工的员工号、姓名、job_id以及salary
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees
WHERE
job_id <> 'IT_PROG'
AND salary < ANY (
SELECT
salary
FROM
employees
WHERE
job_id = 'IT_PROG')
需求:返回其他job_id中,比job_id为‘IT_PROG’部门所有工资低的,员工的员工号、姓名、job_id以及salary
SELECT
employee_id,
last_name,
job_id,
salary
FROM
employees
WHERE
job_id <> 'IT_PROG'
AND salary < ALL (
SELECT
salary
FROM
employees
WHERE
job_id = 'IT_PROG')
45 -3 聚合函数不能嵌套
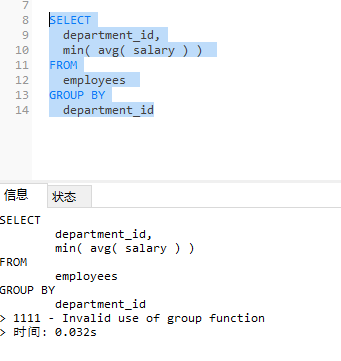
需求:查询平均工资最低的部门id
MySQL不支持聚合函数嵌套,在oracle中可以。
SELECT
department_id,
min( avg( salary ) )
FROM
employees
GROUP BY
department_id
所以需要把第一次查询结果作为一张表,再查一次:
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) = (
SELECT
min( avg_sal )
FROM
( SELECT department_id AS department_id, avg( salary ) AS avg_sal FROM employees GROUP BY department_id ) t)
方式2:
SELECT
department_id
FROM
employees
GROUP BY
department_id
HAVING
AVG( salary ) <= ALL ( SELECT avg( salary ) AS avg_sal FROM employees GROUP BY department_id )
p46-相关子查询案例分析
46-1 查询员工中工资大于本部门平均工资的员工的last_name,salary,department_id
SELECT
o.last_name,
o.salary,
o.department_id
FROM
employees AS o
WHERE
o.salary >(
SELECT
avg( salary )
FROM
employees AS i
WHERE
i.department_id = o.department_id
GROUP BY
i.department_id
)
方式2:将各部门平均工资查出来,作为一张表,进行联表查询:
SELECT
e.last_name,
e.department_id,
e.salary
FROM
employees AS e,(
SELECT
department_id,
avg( salary ) AS avg_sal
FROM
employees
GROUP BY
department_id
) t
WHERE
e.department_id = t.department_id
AND e.salary > t.avg_sal
46-2 在ORDER BY中使用相关子查询:查询员工的employee_id,salary,department_id,并且按照department_name(在另一张表)进行排序
SELECT
employee_id,
salary,
department_id
FROM
employees AS e
ORDER BY
(
SELECT
department_name
FROM
departments AS d
WHERE
d.department_id = e.department_id
)
在查询中,除了GROUP BY 和LIMIT中,都可以声明子查询
46-3 若employees表中的employee_id与job_history表中的employee_id相同的数目不小于2,则输出这些相同id的员工的employee_id,last_name和job_id
SELECT
e.employee_id,
e.last_name,
e.job_id
FROM
employees AS e
WHERE
2 <=(
SELECT
count(*)
FROM
job_history AS j
WHERE
j.employee_id = e.employee_id)
46-4 exist和not exist关键字
匹配每一条记录,如果满足条件,就不再往下匹配了,返回true,不满足则一直往下匹配子查询中的记录。
查询公司管理者的employee_id,last_name,job_id,department_id
方式1:自连接
SELECT DISTINCT
emp.employee_id,
emp.last_name,
emp.job_id,
emp.department_id
FROM
employees emp,
employees mgr
WHERE
emp.employee_id = mgr.manager_id
方式2:子查询
SELECT
employee_id,
last_name,
job_id,
department_id
FROM
employees
WHERE
employee_id IN ( SELECT manager_id FROM employees )
方式3:使用exist关键字和相关子查询
SELECT
employee_id,
last_name,
job_id,
department_id
FROM
employees AS e1
WHERE
EXISTS (
SELECT
*
FROM
employees AS e2
WHERE
e1.employee_id = e2.manager_id)
查询departments表中不存在于employees表中的部门的department_id和department_name
方式1:右外连接
SELECT
d.department_id,
d.department_name
FROM
employees AS e
RIGHT JOIN departments AS d ON e.department_id = d.department_id
WHERE
e.department_id IS NULL
方式2:使用not exist关键字和相关子查询
SELECT
department_id,
department_name
FROM
departments AS d
WHERE
NOT EXISTS (
SELECT
*
FROM
employees AS e
WHERE
e.department_id = d.department_id
)